This is a fairly common issue that happens randomly on WordPress websites which has the catastrophic impact of bringing the entire website offline resulting in users seeing the error whenever they try and load a page on the website.
This can feel quite daunting when you first see this error, but don’t worry as there is a methodical process to solving this issue. As with many things with WordPress, there are many different root causes of these kinds of issues, so it’s simply a case of debugging things to identify what is causing the issue which will allow you to identify the next steps to solve the issue.
The common root causes of the “Error establishing a database connection” on WordPress can be;
Incorrect database connection details in your /wp-config.php file (unlikely if you haven’t actively changed this recently – more common for new manual installations of WordPress)
Corrupt Plugin files which can often occur after recent updates to Plugins
Corrupt database table(s) which need repairing
So let’s look at how to debug each of the common problems.
Check Database Connection Details
Simply open your /wp-config.php file and confirm that the details are correct for the following settings;
define(‘DB_NAME’, ‘your_database_name’);
define(‘DB_USER’, ‘your_database_username’);
define(‘DB_PASSWORD’, ‘your_database_password’);
define(‘DB_HOST’, ‘localhost’);
Unless you’ve recently changed these settings between the last time the website was working and the time you are seeing the “Error establishing a database connection” error appeared, then it is unlikely that this is the root cause of the issue.
Check for Corrupt Plugin Files
Whether you are manually updating your Plugins or you have these configured to automatically update (which is highly recommended) both failed or successful Plugin updates can result in this error showing. To quickly debug this, simply rename the /wp-content/plugins folder to /wp-content/plugins-disabled
When WordPress cannot find a Plugins folder it simply disables all plugins from running whenever you load a page on your website. So this is a quick test where you can simply rename the folder, then try refreshing the website again to see if the error has disappeared.
If that has solved the problem, then you simply need to rename the folder back to it’s original name, then methodically disable one plugin at a time by repeating that same process on the sub-folders for the individual Plugins to determine which plugin is causing the issue.
Repair Corrupt Database Tables
This one is a little more challenging to debug manually, but thankfully recent versions of WordPress have a handy tool to identify issues and try and automatically fix the problem.
Firstly, you need to edit your wp-config.php file and add the following line in;
define(‘WP_ALLOW_REPAIR’, true);
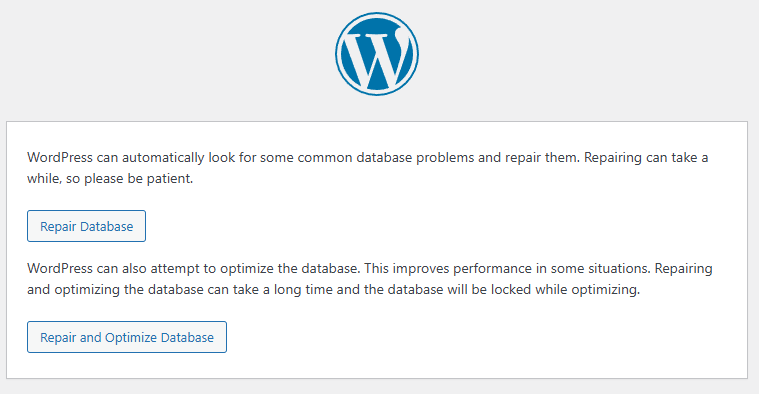
Once that setting is turned on, you can visit https://example.com/wp-admin/maint/repair.php (naturally replacing the domain name with the one you are working on)
You may see a page similar to the above or one full of errors and database tables – either way, you will see the options to either;
Repair Database
Repair and Optimize Database
So give those a go.
All being well, this will solve the issue and your website will be back online.
There are also a few other handy debugging steps related to this such as if you’re running phpMyAdmin then you will probably notice that the table appears locked and will often say that the table is “in use” which is a strong indicator that there is an issue.
It is possible to fix this issue via phpMyAdmin by selecting the table and selecting the option to Repair Table which effectively does the same thing the above automated process has done.
And if you’re running on cPanel, then it’s handy to view the cPanel error log for the specific cPanel account by running the command via SSH;
cd /home/cpanel-account-username/public_html
tail error_log
Which will output any errors that the site is having. It’s important to note that for this step to work, you must have your WordPress error logs turned on in your wp-config.php file and must have loaded the page again so the errors actually get written to the log.
AI Summary of the legislation first published earlier today in Ireland….. Because no-one has the time to read the 180 page legal document….. But it’s probably important to do so to validate this AI content when it comes to legislation.
Add your thoughts in the comments about what you think this is going to mean going forwards….. 🧐🧐🧐🧐🧐
The document outlines the General Scheme of the Regulation of Artificial Intelligence Bill 2026, detailing the establishment, functions, and governance of the AI Office of Ireland, along with provisions for market surveillance, supervision, enforcement, and administrative sanctions related to AI systems.
Long Title and Purpose of the Bill
The Bill aims to implement the EU AI Regulation (2024/1689) and establish the AI Office of Ireland.
It amends several existing acts to align with the new AI regulatory framework.
Short Title, Commencement, and Citation
The Act is titled the Regulation of Artificial Intelligence Act 2026.
It will commence on a date set by the Minister, allowing for phased implementation.
Definitions and Interpretations
Key terms such as “AI Act,” “Economic Operator,” and “Market Surveillance Authority” are defined.
The definitions ensure clarity and consistency in the application of the Act.
Establishment of the AI Office
The AI Office of Ireland will be established as a statutory body on a designated day.
It will serve as the central authority for AI regulation in Ireland.
Functions and Powers of the AI Office
The Office will facilitate enforcement of the AI Act, promote AI innovation, and provide technical expertise.
It is designated as a Market Surveillance Authority and a Single Point of Contact for the EU.
CEO Accountability and Delegation
The CEO is accountable to the Board for any delegated functions, ensuring clear responsibility and oversight.
The CEO can revoke delegations with Board consent, allowing flexibility in operational management.
Delegated functions do not include those with conditions prohibiting further delegation, preserving Board integrity.
Resignation and Removal of CEO
The CEO can resign by notifying the Minister, effective upon receipt.
The Minister can remove the CEO for incapacity, misbehavior, or necessity for effective Office performance.
A statement of reasons for removal must be provided to the CEO.
CEO Accountability to Committees
The CEO must provide evidence to the Public Accounts Committee on financial transactions and operational efficiency.
The CEO cannot question government policies during testimony.
This accountability framework supports the Office’s independence and financial control.
Board Membership and Governance
The Board consists of 7 members, including the CEO as an ex officio member.
Members are appointed by the Minister, ensuring relevant experience and gender balance.
Terms of office are limited to 5 years, with a maximum of 10 years for reappointments.
Disclosure of Interests and Confidentiality
Individuals involved with the Office must disclose any beneficial interests in matters under consideration.
Non-disclosure may lead to removal or contract termination.
Confidential information must not be disclosed without authorization, ensuring protection of sensitive data.
Market Surveillance Authorities and Their Powers
Market Surveillance Authorities (MSAs) are designated to ensure compliance with the EU AI Act 2024/1689.
They possess extensive powers under Article 14 of the Market Surveillance Regulation, including document requests, inspections, and penalties.
Designation of MSAs in Ireland
Six authorities in Ireland are automatically designated as MSAs for the AI Act, as per S.I. No. 366 of 2025.
Additional public bodies are also designated for specific sectors, ensuring comprehensive market surveillance.
Incident Reporting and Management
MSAs are responsible for receiving reports of serious incidents from providers of high-risk AI systems.
Procedures for managing these reports align with the Market Surveillance Regulation and require timely notifications to relevant authorities.
Temporary Authorisation for High-Risk AI Systems
MSAs can grant temporary authorisation for high-risk AI systems in exceptional circumstances, such as urgent public needs.
Authorisations are limited in scope and require ongoing monitoring by the provider.
Cooperation and Information Sharing
MSAs may enter cooperation agreements to facilitate information sharing and streamline enforcement.
They are also required to maintain confidentiality and cybersecurity measures in their operations.
Indemnity for Authorised Officers
Authorised officers are indemnified by the Market Surveillance Authority (MSA) for actions taken in good faith while performing their duties.
This indemnity protects against personal liability for actions such as inspections and issuing notices.
Powers of Authorised Officers
Authorised officers can enter premises, inspect products, and require information to ensure compliance with the AI Act.
They have the authority to secure premises, take samples, and detain products suspected of non-compliance.
Procedure for Risky AI Systems
MSAs must evaluate AI systems suspected of presenting risks, especially to vulnerable groups.
If non-compliance is found, operators must correct issues or withdraw systems within 15 working days.
Contravention and Prohibition Notices
Authorised officers can issue contravention notices for regulatory breaches, requiring corrective actions.
Prohibition notices can be served for serious risks, directing immediate compliance or withdrawal from the market.
Administrative Sanctions and Appeals
Economic operators can appeal contravention or prohibition notices to the District Court.
The MSA may impose penalties for non-compliance, ensuring enforcement of the AI Act.
Ministerial Rules for Adjudication Process
The Minister for Enterprise can create rules for referrals and adjudication applications.
This power is centralized to ensure consistency across market surveillance authorities.
Nomination and Appointment of Adjudicators
The AI Office of Ireland nominates adjudicators based on expertise.
The Minister appoints these nominees, ensuring independence and adherence to prescribed criteria.
Independence and Conduct of Adjudicators
Adjudicators must operate independently and recuse themselves in case of conflicts of interest.
The Minister will implement regulations to uphold this independence and ensure proper conduct.
Regulations for Adjudicator Procedures
The Minister must consult relevant Ministers when creating regulations for adjudicator conduct.
Regulations will cover appointment terms, remuneration, and procedures for revocation of appointments.
Evidence and Hearing Procedures
Adjudicators can summon witnesses and require evidence for oral hearings.
The rules of evidence apply, and hearings are generally public unless special circumstances arise.
Financial Penalties for Regulatory Breaches
Adjudicators determine financial penalties based on various factors, including breach severity and operator size.
Maximum penalties can reach up to €35 million or 7% of annual turnover for serious breaches.
Admissibility of Evidence in Proceedings
Documents admissible as evidence include oral statements, electronic messages, and recordings.
Chapter 3 of the Civil Law and Criminal Law (Miscellaneous Provisions) Act 2020 applies to proceedings under this Act.
Restrictions on Disclosure of Information
Statements made under compulsion are not admissible in criminal proceedings.
Confidential information obtained by authorities cannot be disclosed without reasonable excuse.
Violations of disclosure restrictions can result in a class A fine or imprisonment.
Appeals and Judicial Review Procedures
Appeals against adjudications must be made within 28 days.
The High Court’s decisions on appeals are final unless exceptional public importance is certified.
Judicial review applications must be made within 28 days of the decision being published.
Functions and Powers of Notifying Authorities
Notifying Authorities must monitor conformity assessment bodies and cooperate with other Member States.
They have powers to require information, conduct assessments, and enforce confidentiality.
Funding Mechanism for Competent Authorities
Competent Authorities can impose levies on regulated entities to fund their functions under the Act.
In simple terms, it’s a glorified Download button….. run at the Command Line.
What is WGET
In reality it’s a WGET Linux Package that is installed on your Linux Operating System of choice which enables you to GET (HTTP Methods) “stuff” over the HTTP/S and S/FTP/S protocols.
These commands are used at the Command Line.
And for those of your reading who have been casually using this on Linux for some time, when you come to trying this same functionality on Windows, you’ll soon realise that this doesn’t work out of the box.
Who knows why….. Let’s just blame Microsoft, who knows?
WGET is such an awesome tool, it’s a bit baffling why this isn’t included in Windows by default. But hey.
WGET for Windows
Thankfully, the world has come to rescue to make WGET for Windows!
So this enables you to use WGET on Windows rather than only on Linux!
The TLDR; is that you can Download WGET for Windows here.
Handy WGET Commands
The basics of WGET is as simple as follows;
“`
wget https://www.example.com
“`
Which will download the index.html page.
What you will often want to do though is download an entire website.
Thankfully there is a handy command for that too…..
“`
wget –page-requisites https://www.example.com
“`
(Note, the above is dash dash, it just looks weird)
And by using that additional flag you can download all of the things required to run that website locally.
You would have thought in 2023 that this would be a 2 second job to do. A well documented thing given Apache is one of the largest open source companies on the planet and Java being the most used language on the planet that powers over 1 billion devices (as their installers used to love reminding us every time 🙂 )
But weirdly, it’s not…
So I thought it would be handy to write a blog post about how to get going in 15 minutes so you can start to have a play. After all, we don’t want people to have 10 years experience in this stuff just to get a basic local development environment up and running.
What we’re going to cover…
Getting the Java Development Kit (JDK) installed
Getting Apache NetBeans IDE installed, which requires the Java Development Kit (JDK) to work
Getting Apache Tomcat installed, so your Apache NetBeans IDE can deploy your web application to the locally running web server so you can see your web application in your web browser
Configuring Apache NetBeans so that it knows about the Apache Tomcat server that is running on your local machine
Seeing everything in action!
So let’s get started.
Getting the Java Development Kit (JDK) Installed
First of all, just get to Google and search for “JDK Download”. I’m not going to give you the exact steps here as Oracle, the people who ‘own’ Java, seem to keep making life ever more difficult every day to download this and now even requires you to create an account with Oracle just to download the software. Rather annoying, but just jump through the latest hoops you have to at the time you are reading this, as anything I write down is going to have changed since the time this blog post was written.
The only thing to mention that you need to keep a record to when you are doing this is the Folder Path of where this is installed. You’ll need this in the next step if the installation of Apache NetBeans IDE doesn’t manage to automatically detect it.
Beginner Development
For greenfield projects, i.e. something brand new, then just download the latest version of the Java Development Kit (JDK). You may get issues when you get onto the next steps, so you may have to loop back on this step and install an older version that is compatible with the other software you are installing.
Unfortunately the different software providers throughout this blog post don’t make it simple to understand what versions are compatible with which other versions. It’s a tad annoying and is a wider problem with the software engineering in general so it’s something your going to have to get comfortable being annoyed about and regularly banging your head against the wall.
Usually there is some half-arsed documentation somewhere buried on the respective websites, but you’ll have the Google the shit out of it to find this basic info unfortunately. But hey, just giving you the heads up.
For now though, just download the latest version of the Java Development Kit (JDK) so you can give this a first attempt.
Working with Existing Projects
If you are working with existing projects, then this is a tad different as you are going to have to work within the constraints of that setup. So you are probably going to have to refer to the project documentation about what versions of what you need to get up and running with ease.
Remember when your Past-Self recommended that you document your development environment and your project technical dependencies so that your Future-Self would be thankful that you did…. Well, if your Present-Self is currently disgruntled with your Past-Self, then let that be a lesson. And document this properly this time round.
Or worse in a corporate setting where this was never documented and you simply have to talk to your software engineering colleagues to try and find the info you need through 1000 questions rather than a 1 page document that gives you everything you need. Well, yeah, good luck with that.
Getting Apache NetBeans IDE Installed
Next step is to get Apache NetBeans IDE installed. Again, just Google for the download link and run through the installation steps.
There is nothing specific to really mention on this step other than that you need to enter the Java Development Kit (JDK) installation folder path as part of the setup. Generally the Apache NetBeans IDE installer detects this automatically and puts that in for you. But you may need to enter this manually if it hasn’t been automatically detected.
Getting Apache Tomcat Installed
Right, this next step is where things get a tad tricky, or at least can do.
Again, just to get started, Google “Apache Tomcat Installation” and you’ll come across a Windows Installer .exe file that you can use to get up and running quickly.
It seems that the last time I installed this (hence the reason for writing this blog post…) this is installed in a bit of a quirky way which actually prevents Apache NetBeans IDE from deploying your application to your Apache Tomcat web server. A tad annoying, and not particularly well documented.
So during the installation process the only details you really need to make a note of are;
Port
Windows Service Name
Tomcat Admin Username
Tomcat Admin Password
Installation Folder Path
These will come in handy in the next section when we configure Apache NetBeans to allow it to talk to Apache Tomcat.
Anyhow, for now, as part of the installation process, it is recommended that you create a Username/Password combo for your local machine so that you can actually use it. It’s a bit of a pain if you have to do this post-installation, so for the purpose of this blog post, we’re going to assume you are doing this as part of your installation procedure.
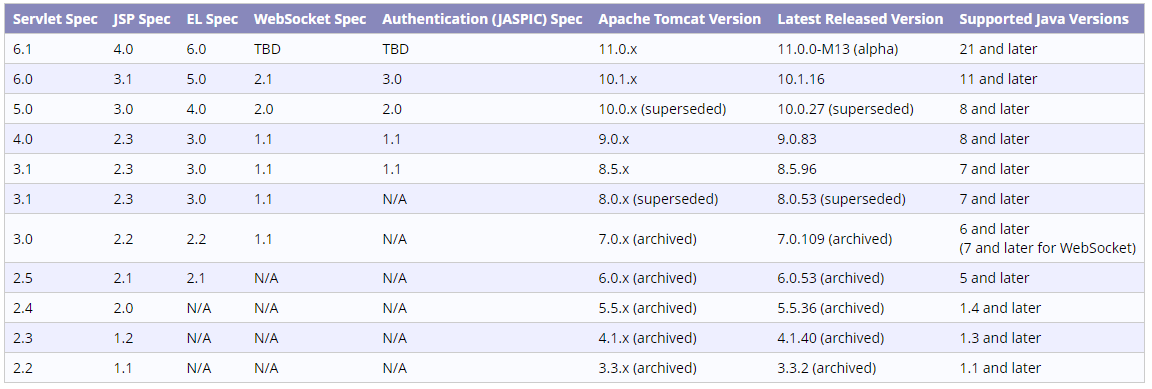
The reason I mentioned a moment ago that this step can get a little tricky is that each version of Apache Tomcat supports a LOT of different specifications and dependencies which can be tough to align – even on your local development environment. There is a “Which Apache Tomcat Version to Use” page which tries to help to simplify things, but honestly, just adds more complexity. Apache Tomcat doesn’t seem to care too much about backwards compatibility for some reason and expects software engineers to try and be a One Man Band just to figure out what they need. You’ll see what I mean with this snippet from that page;
Simple, right?!?!?
So basically you need to make sure that everything aligns with the different versions mentioned above;
Apache Tomcat Version
Java Development Kit (JDK) Version
Servlet Specification Version, required for developing Web Applications
Java Server Pages (JSP) Specification Version, required for developing Web Applications that are of monolith in nature – This is essentially the ‘front end’ part of your Web Application
Expression Language (EL) Version, required for developing Web Applications that want to handle data that is passed from the ‘back end’ (aka. the Java Servlet Specification) to the ‘front end’ (aka. the Java Server Pages JSP Specification) so that you can essentially loop through lists and such like to output the data that you need from variables, or much simpler outputting of data stored in variables
WebSocket Specification, if your web application is using cool tech like this (probably not on your first Hello World web application!)
So I’m going to assume you’ve studied all of these different specifications over the last 5 years and fully memorised 1000s of pages worth of documentation to be able to easily know this information. Right?
Of course not. No-one has. But hey, Java often likes to make things more difficult than they need to be. But don’t let that put you off, it brings so much value over scripting languages that are all the rage at the moment.
Anyhow, for now, just go with the most recent version to get started.
Configuring Apache NetBeans to Talk to Apache Tomcat
The next step is to configure Apache NetBeans IDE to talk to your Apache Tomcat service. To achieve this, there are two core steps involved;
Configuring Apache NetBeans by adding a Server as a Service to your IDE
Tweaking the way that the Apache Tomcat web server Windows Service runs
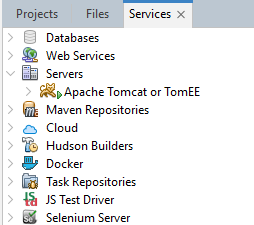
Add Apache Tomcat Web Server to Apache NetBeans IDE as a Service
So let’s look at the easy step first. Simply right click on the Servers section and follow the steps through to add your Apache Tomcat server. You’ll need those details you made a note of earlier to connect to the right one as you may have multiple of these running on your local development environment over time to support different projects.
You can see in the above screenshot that I have already added the Apache Tomcat web server which is why it is showing up in the list already.
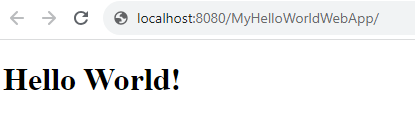
Error You Will Receive If You Try to Build & Deploy a Web Application Right Now
So it’s important to explain what error you will receive if you try to build your first Hello World Web Application right now and deploy it by pressing the green play button. The error messages can be a tad cryptic and you’ll also need to check the catalina.log file for further insights, which can be a bit of an unknown unknown when getting started with Java software development.
Building war: C:\Users\Michael Cropper\NetBeans Projects\MyHelloWorldWebApp\target\MyHelloWorldWebApp-1.0-SNAPSHOT.war
------------------------------------------------------------------------
BUILD SUCCESS
------------------------------------------------------------------------
Total time: 1.232 s
Finished at: 2023-12-01T23:04:45Z
------------------------------------------------------------------------
Deploying on Apache Tomcat or TomEE
profile mode: false
debug mode: false
force redeploy: true
Undeploying ...
undeploy?path=/MyHelloWorldWebApp
OK - Undeployed application at context path [/MyHelloWorldWebApp]
In-place deployment at C:\Users\Michael Cropper\NetBeans Projects\MyHelloWorldWebApp\target\MyHelloWorldWebApp-1.0-SNAPSHOT
deploy?config=file%3A%2FC%3A%2FUsers%2FMICHAE%7E1%2FAppData%2FLocal%2FTemp%2Fcontext9586713857740903372.xml&path=/MyHelloWorldWebApp
FAIL - The application [/MyHelloWorldWebApp] is already being serviced
I’m actually pretty sure the first time I did this, I got this error message instead. The above one sems to be ever so slightly different final line in the error message. But either way, it fails, which means that it hasn’t been deployed.
FAIL - Failed to deploy application at context path [/MyHelloWorldWebApp]
Which I’m sure you’ll agree isn’t actually that much of a helpful error message.
So to get to the bottom of what is really going on, you need to get into your Apache Tomcat logs, specifically the catalina.out file (or the one with today’s date on).
On a Windows machine, this is going to be located at: C:\Program Files\Apache Software Foundation\Tomcat 10.1\logs
Which is the location of where you installed Apache Tomcat earlier.
What was interesting when checking this is that this is the actual error that was reported when the error for “FAIL – Failed to deploy application at context path” came up;
“30-Nov-2023 21:32:39.679 SEVERE [http-nio-8080-exec-2] org.apache.catalina.startup.ExpandWar.copy Error copying [C:\Users\MICHAE~1\AppData\Local\Temp\context3064853893058586338.xml] to [C:\Program Files\Apache Software Foundation\Tomcat 10.1\conf\Catalina\localhost\MyHelloWorldWebApp.xml] java.io.FileNotFoundException: C:\Users\MICHAE~1\AppData\Local\Temp\context3064853893058586338.xml (Access is denied)”
Which made me think…. that’s odd. I installed Apache Tomcat via a Windows Installer using the exact same Windows logged in user, so I can only assume that one of the installers is doing a bit of crazy on Windows and being overly secure by segmenting which user is running the application – which would prevent User A from accessing anything in User B without relevant permissions. Something you’d really only know a lot about after dealing with a lot of Linux permissions issues historically, and if you’re a noob with this stuff is probably going to be something that would be a complete blocker for you to get past.
Which brings us onto the next step for how to solve this…
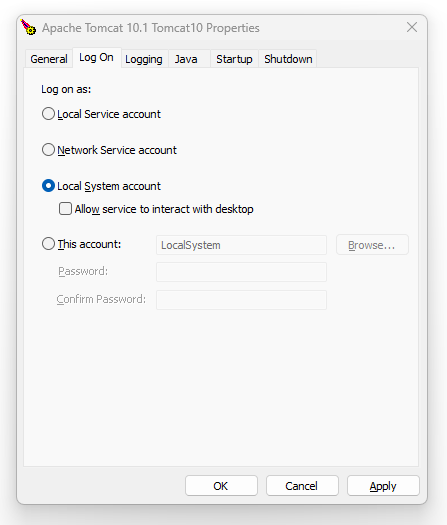
Tweaking the way that the Apache Tomcat web server Windows Service runs
So when you just installed Apache Tomcat via the Windows Installer you will notice that you have an Apache Tomcat service running in your Windows Task Bad as a background service. It doesn’t auto-start on reboot by default, so you may have to start the service if you have rebooted since you installed the software.
So you need to go into the Windows Task Bar and find the Apache Tomcat software that is running and click on the Configure option. From here, you need to go to the Log On tab and change this from the default “Local Service Account” over to “Local System Account”
Do that, click Apply and then Ok. Then finally restart the Apache Tomcat service if it is already running and you’ll be good to go.
Seeing Everything in Action
Awesome. So now you’ve got all this up and running, you’ll be able to click the Play button in the Apache NetBeans IDE to run your project and it will deploy your web application successfully to your Apache Tomcat web server so you can interact with it in your web browser.
Summary
Hopefully this is a helpful guide for how to get an Java local development environment up and running in no time so that you can start to develop web applications using the power of Java.
Yes, it’s a bit of a pain as you get deeper into Java, but for getting started it’s mainly about making sure the different versions of the software you are running are aligned and designed to support each other. The documentation is often pretty awful so if things don’t quite go to plan, just lots of Google’ing will help you get to where you need to be.
So, where do I start with this topic. It’s complex…
I didn’t really know what to title this blog post as, since it’s complex.
Specifically my personal problem at hand was to look at how to prevent missing dates between two dates when needing to report on basic challenges such as Show Number Of X Between Two Dates. And since the basic queries such as SELECT COUNT(*) FROM table_x GROUP BY my_date_field; tends to work absolutely fine in scenarios where things are happening daily, it dramatically fails when things often happen over longer time frames. Instead, it’s important that the actual dates between two dates are the primary axis on reporting on this data.
Quite surprisingly, this seems to have been a fairly challenging thing to achieve prior to MySQL 8, so this blog post is purely going to look at MySQL 8 and beyond for how to achieve this.
MySQL isn’t really designed to work with while loops. But in every modern programming language while loops are simple.
i.e.
while(x = true){
doSomething();
}
Etc.
Great, then let’s wrap the complex while loops in the code, and leave MySQL for the basics of data retrieval.
Yeah… but there is a thing called performance, and that doesn’t really work on large scale data sets with millions of records…
It’s imperative that the data access complexities are pushed as low into the tech stack as possible to improve efficiency, on so many levels. Aka. Don’t put things in the code layer that would be better handled at the data layer, aka. MySQL.
So, historically, if you wanted to perform a while loop in a MySQL query you would probably end up resorting to a Stored Procedure in one way or another. Sorry DABs (aka. Database Administrators) but when software requires the use of Sored Procedures then there is probably something fundamentally wrong under the hood.
Basic While Loop in MySQL using WITH RECURSIVE
So, let’s get back to basics. How do we do a basic loop in MySQL 8. How do I count from 1 to 10 using pure SQL?
Turns out, it’s “pretty simple” (as everything is when you know how) but the syntax is a bit of a challenge. So let’s dig into that next.
How to Count from 1 to 10 in MySQL 8 Using Recursive Queries
The simple solution to this is as follows;
WITH RECURSIVE myRecursiveExpressionName(iCanCount) as (
SELECT 1
UNION ALL
SELECT
iCanCount + 1
FROM
myRecursiveExpressionName
WHERE
iCanCount < 10
)
SELECT
*
FROM
myRecursiveExpressionName
ORDER BY
iCanCount ASC
;
Which will produce a nice output as follows when running the query;
1
2
3
4
5
6
7
8
9
10
Great. We can do some simple sequential “stuff”.
How to Use MySQL to Get the Dates Between Two Dates for Reporting
So, now it’s time to put this into practice. Let’s get a list of dates that we can use that are the definitive list of dates between two dates, such as the kind of thing that you would use in a situation that is measuring data and performance and trends between two date periods.
WITH RECURSIVE allDatesBetweenTwoDates(myRecursiveExpressionName) as (
SELECT '2023-10-01'
UNION ALL
SELECT
myRecursiveExpressionName + INTERVAL 1 DAY
FROM
allDatesBetweenTwoDates
WHERE
myRecursiveExpressionName < '2023-10-12'
)
SELECT
*
FROM
allDatesBetweenTwoDates
ORDER BY
myRecursiveExpressionName ASC
;
Query Syntax
OK, this is all well and good with the examples. But what does it mean above? It’s fairly new syntax with MySQL and it isn’t easy to understand what it is actually doing. And the official documentation can be a tad difficult to interpret.
So let’s dig into this in a little more detail for what this all means in practice, I’ve added a few comments to the iCanCount example which helps explain what is going on…
-- MySQL While Loop
-- Think about this whole section with the WITH RECURSIVE bit as kind of like an in-memory virtual table with one column, called ‘allDatesBetweenTwoDates
WITH RECURSIVE myRecursiveExpressionName(allDatesBetweenTwoDates) as (
-- Non-Recursive Select Part...
-- Return initial row set
-- aka. Start Date
SELECT '2023-10-01'
UNION ALL
-- Recursive Select Part...
-- Return additional row sets
-- aka. End Date, with a stop expression via the WHERE clause
SELECT
allDatesBetweenTwoDates + INTERVAL 1 DAY
FROM
myRecursiveExpressionName
WHERE
allDatesBetweenTwoDates < '2023-10-12'
)
SELECT
allDatesBetweenTwoDates
FROM
myRecursiveExpressionName
ORDER BY
allDatesBetweenTwoDates ASC
;
Which then nicely produces the a row for every date between those two dates;
2023-10-01
2023-10-02
2023-10-03
2023-10-04
2023-10-05
2023-10-06
2023-10-07
2023-10-08
2023-10-09
2023-10-10
2023-10-11
2023-10-12
Brilliant. Next it’s just back to your good old easy MySQL stuff to the data you want on those dates to join to the table of your choice to get the additional data you need. i.e. as a simple example;
WITH RECURSIVE myRecursiveExpressionName(allDatesBetweenTwoDates) as (
SELECT '2023-09-06'
UNION ALL
SELECT
allDatesBetweenTwoDates + INTERVAL 1 DAY
FROM
myRecursiveExpressionName
WHERE
allDatesBetweenTwoDates < '2023-10-06'
)
SELECT
allDatesBetweenTwoDates
, IFNULL(SUM(my_table.my_summable_column), 0) -- Important to add the IFNULL check here to avoid NULLs returning as you can’t graph a NULL value
FROM
myRecursiveExpressionName
LEFT JOIN my_table ON myRecursiveExpressionName.allDatesBetweenTwoDates = my_table.created_date
GROUP BY
myRecursiveExpressionName.allDatesBetweenTwoDates
ORDER BY
allDatesBetweenTwoDates ASC;
I have to mention though, while that last bit looks easy – this is going to be heavily dependent on your data, data quality and data relationships to get the exact data you need. This bit soon gets tricky when you have to include a WHERE statement, since the second you introduce a WHERE to filter data such as my_table.some_column_you_want_to_filter_on, then this will instantly get you back to the starting point as it removes all records where you just got a NULL/0 value, which is essentially the same problem at the start when trying to run;
SELECT my_date, COUNT(*) FROM my_table GROUP BY my_date;
Which fails miserably when there are missing records on certain dates. It’s surprising all of this is needed in this day and age. If only MySQL could create some kind of “WITH FILL MISSING DATES BETWEEN(fromDate, toDate)” kind of function/syntax to abstract all this kind of workings.
What are your thoughts reading this blog post, please leave a comment.
I’ve been a member of Stack Overflow for many many years in various guises. And over the years I’ve been ever more disengaged and disgruntled with the community on there. It’s such a shame, as it’s actually quite a handy platform if it weren’t for some members of the community. I don’t wish to tarnish the great people out there in the community who have genuinely helped me and others along the way. Hat’s off to you, the good people in the community provide real value.
I’m not going to listing all the problems about Stack Overflow in this blog post, simply do a quick Google search for “stack overflow community known problems” and you’ll soon see results including words such as “toxic”.
So I’m writing this blog post to ask Stack Overflow… Have you really changed?
What do you think as someone reading this blog post and is a user of Stack Overflow?
In a recent discussion with moderators on SO, I’ll post the full chat below for transparency, but the summary is that you have to only ask good questions (whatever that means…), and you can’t provide answers that the moderators disagree with, and content censorship is ripe.
Personally, I’d say the community is probably more toxic today than it has been in years. So I’m not seeing any positive change off the back of their acknowledgement 5 years ago of the problem.
Full transcript…..
Moderator Private Message from moderators sent yesterday to Michael Cropper’s user avatar Michael Cropper Hello,
We’re writing in reference to your Stack Overflow account:
Some of your recent interactions with other community members have violated our Code of Conduct. We get it; anyone who’s ever tried to engage with others online has probably been tempted to lash out at someone else. However, on our sites, we do require all participants to interact in a professional and civil manner. If another user has wronged you in some way, please do not respond in kind. Simply flag the content for moderator attention and move on.
In particular, we would like to call out the following interactions as being problematic and having contributed to sending this message:
“Not a gripe on your question as you clearly don’t know the basics (you will in time young Padawan…) but…. JavaScript Frameworks that aim to “simplify” things are just useless. You can’t skip the foundations.
Don’t take this personally, but if you don’t know this, you probably shouldn’t be using a JavaScript framework such as Express.js (or any other!). Using these kinds of frameworks is only going to hinder your growth and learning experience. Express.js (amongst many others) will probably be dead in the next few years and everyone is onto the next flavour of a JavaScript framework that has equally as many problems.”
“Given up with D3 JS. I’ve just been blocked from their community Q&A for asking questions similar to this (and other similar ones) for a basic working example. Only asking on StackOverflow because their official support channels are so bad.
Thanks for the people who have been trying to help on StackOverflow, much appreciated and some great ideas that have helped to try various solutions (Even though ultimately none of them worked, if only D3 could provide a pure JavaScript example without the reliance on JavaScript Template Literals, but they don’t have that…).
Not going to be exploring D3 further in any way at all based on the way I’ve been treated from their official support channels. Absolute bunch of clowns. If can’t get a basic HelloWorld example working, zero chance of a commercial conversation.”
You’ve left several of these “commentary answers”, and in the last instance, you made a screenshot of the answer that was deleted for not really being an answer. We expect answers to answer the question. If you want to comment, you have the commenting privilege. In addition, please don’t comment on how or little knowledge you think question posters have. Such assumptions never end well.
Please refrain from this behavior in the future. We take the Code of Conduct very seriously and we encourage you to take a moment now to review it. We’d like you to not only consider your intent, but also the impact your interactions are having on others. And while we hope it’s unnecessary, we want to make sure that you’re aware that future incidents of this type could result in your profile being suspended.
Regards, Stack Overflow Moderation Team
add a new private reply from Michael Cropper to Andy ♦; Baum mit Augen ♦; blackgreen ♦; Bohemian ♦; Brad Larson ♦; ChrisF ♦; Cody Gray ♦; deceze ♦; Dharman ♦; Flexo ♦; Henry Ecker ♦; Jean-François Fabre ♦; josliber ♦; Machavity ♦; Makyen ♦; Martijn Pieters ♦; Michael Myers ♦; Rob ♦; Russia Must Remove Putin ♦; Ry- ♦; Ryan M ♦; Samuel Liew ♦; sideshowbarker ♦; Stephen Rauch ♦; Undo ♦; user229044 ♦; Zoe stands with Ukraine ♦
==========
More fun from the SO community #FacePalm. Unfortunately this is why both I and many others disengage because it’s painful to engage. There are so many judgemental people in this community it’s such a shame as it actually isn’t helpful and this moderator message is a prime example of this in action.
Community downvoting things for no reason for a “bad question” – There is no such thing as a bad question. When did SO become a Q&A when someone asks “I want an apple” and someone gets downvoted for saying “Have you thought about having a banana as part of your 5 a day” These types of basic blindly asking and answering questions help no-one in the long run without context – copying and pasting code snippets as answers does not help the person asking the question for them to have a deeper understanding of why.
There are some really helpful people on SO, but it’s tainted by so many idiots unfortunately, and often in mod/senior positions controlling the content about what is acceptable and what isn’t. And the fact that this message is coming through is unfortunately part of the problem. Don’t take it personally, I don’t know any of you folk in the CC. I’m sure you’re all great folk, but honestly, this message just makes me disengage further from SO.
As for the question re. the JS Framework. I stand by that as a good solid answer that is going to help the person asking the question to move forward in their understanding. You may disagree, that’s your choice. I can’t even find that question any more on the site, probably because some other mod decided it was also a bad question to ask and has since removed it. Pretty awful behaviour to do this to a noob asking the question from memory (or the search function is awful and I can’t find the question again…). It’s best for the person asking the question to determine if the answer is good or not, not some mod hiding behind an alias and a keyboard.
As for the D3 JS question. That was MY question, and if it’s frowned upon to provide an honest answer to my own question, then there is no hope left in the world of SO. I don’t know how anyone other that me could accept an answer to my own question. You may not agree with my answer to my question, and that’s your choice. Doesn’t mean it’s a bad answer just because you don’t like it.
As for the SO mods censoring content… I mean… that also never really ends well with censorship.
Honestly though, this chat is just the final straw for me with SO. I will not be answering or commenting on anything for anyone else in the community to help them unless it directly helps me. It’s such a shame because I’ve always taken the mindset of pay it forward. If I get something from SO, then I try to take some time out of my day and provide a few insights and help others out along the way answering questions that I can help get them moving in the right direction – sorry if that’s not in the specific way you like but quite frankly if you are criticising someone for providing value then you’ve lost the plot as a platform. Unfortunately I won’t be doing that any more. Feels as though I’m wasting my time engaging with SO.
Good luck with the future. I’ll probably just engage with ChatGPT from this point forward, at least it doesn’t answer back and judge.
SO seriously needs to look deep and hard at the mods throughout this platform if it has any hope of surviving in the future.
Seems like nothing has really changed in 5 years….. https://stackoverflow.blog/2018/04/26/stack-overflow-isnt-very-welcoming-its-time-for-that-to-change/
Note: This blog post is entirely generated by AI with the prompt “Write a blog post titled “What is Docker” which is around 2000 words in length and include sub-headings to make the content easy to read. ” ….. Leave a comment on what you think…..
Docker is an open-source platform that automates the deployment, scaling, and management of applications inside containers. In simple terms, it provides a way for developers to package their applications and dependencies into a container, which can then run consistently on any system that has Docker installed.
Containers vs Virtual Machines
One of the key differences between Docker and traditional virtualization methods like Virtual Machines (VMs) is that containers share the host system’s operating system (OS) kernel, while VMs run on a full copy of the host’s OS. This makes containers much lighter and more efficient than VMs, as they don’t require the same amount of system resources or disk space.
Another important difference is that containers are isolated from one another, but share the host’s OS. This means that each container runs its own application and dependencies, but they are all running on the same underlying system. In contrast, VMs are completely isolated from one another and run their own OS, which can lead to compatibility issues between different systems.
Why use Docker?
Docker provides several benefits over traditional virtualization methods:
Portability: Docker containers can run on any system that has Docker installed, making it easy to move applications between development, testing, and production environments.
Scalability: Docker makes it easy to scale applications by adding or removing containers as needed, without having to reconfigure the underlying system.
Isolation: Each Docker container runs in its own isolated environment, which helps to ensure that applications don’t interfere with one another.
Consistency: Docker ensures that applications run consistently across different systems, as they are packaged with all of their dependencies.
Ease of use: Docker provides a simple and straightforward way to manage containers, making it easy for developers to focus on writing code instead of dealing with complex infrastructure.
Docker Architecture
Docker uses a client-server architecture, with the Docker client communicating with the Docker daemon, which is responsible for building, running, and managing containers.
The Docker client and daemon can run on the same system, or they can communicate over a network. The Docker client sends commands to the Docker daemon, which then performs the requested actions.
Docker Hub
Docker Hub is a public repository for Docker images, which are pre-built packages that include everything needed to run a specific application or service.
Developers can use images from Docker Hub to quickly get started with building and deploying their applications, or they can build their own images and upload them to Docker Hub for others to use.
Dockerfile
A Dockerfile is a script that contains instructions for building a Docker image. It specifies the base image to use, the application and dependencies to include, and any configuration information that the image needs.
Once the Dockerfile has been created, developers can use the Docker build command to build the image and create a container from it.
Getting Started with Docker
Getting started with Docker is straightforward, as it only requires a few basic steps:
Install Docker: To start using Docker, you’ll need to install it on your system. Docker is available for a wide range of platforms, including Windows, macOS, and various Linux distributions.
Download a Docker image: You can either download a pre-built image from Docker Hub or build your own image using a Dockerfile.
Run a container: Once you have an image, you can use the Docker run command to create a container from it and start it running.
Conclusion
Docker is a powerful platform that makes it easy to
Commentary on my opinion of the quality of the ChatGPT generated blog post
Honestly….. Not bad. Technically accurate too. But….. It’s only ~500 words in length, the content is very surface level and nothing really makes sense unless you know this stuff already which kind of makes it a bit pointless. The challenge here is that these topics are complex, the documentation is complex, there are lots of moving parts and actually the whole benefit to writing blog posts is not to write a high level overview of the topic, but to help readers truly understand so they can anchor their existing knowledge towards a new topic so they can get up to speed quickly.
Very gimmicky, entertaining but when it comes to something I would deem as high quality, it’s a long way off. I do like the headings it introduced though (formatted manually), but in reality, nothing that you can’t easily create the structure of a blog post with a tiny bit of research on the topic before jumping straight in.
This is a topic that comes up quite infrequently for many people and for most, never. It’s also one of the topics that is significantly more complex than it should be and one that is fairly poorly documented online about how to do this properly. Fundamentally this is a basic Copy & Paste exercise at best, but it’s made ridiculously complex by the underlying technical gubbins. So hopefully this blog post can clear up the steps involved and some of the considerations you need to make.
Old and New Disks
Disks come in many different shapes and sizes both conceptually and physically, with varying connectors and different underlying technologies. The nuances of these are beyond the scope of this blog post, but to put a few basics down to help conversation let’s look at a few of these at a high level.
We’ve previously covered off topics on the Performance of SSDs VS HDDs so take a look at that for some handy background info.
Summary being that you essentially have two types of hard drives;
Mechanical Hard Disk Drive (HDD) – Has moving parts
Solid State Drives (SSD) – Has no moving parts
See the above blog post for further insights into the differences.
Anyhow, the important point being for the purpose of cloning a hard disk is that you need to know the details of what you are going from and what you are moving to. Get this wrong and you can seriously mess things up in a completely un-recoverable way, so please be careful and if you aren’t sure what you are doing, don’t proceed and instead pass this onto a professional to do this for you.
Disk Connectors – IDE VS SATA
For the sake of simplicity, the two core connectors for disk drives fundamentally fall into either IDE (old) and SATA (new). Yes, the teckies who are reading this will say that this is garbage, and it is. But, in reality, for those reading this blog post, this is likely going to cover 99% of the use case.
In reality there are many types of disk connectors from PATA, SATA, SCSI, SSD, HDD, IDE, M.2 NVMe. M.2 SATA, mSATA, RAID, Host Bus Adapters (HBA) and more (and yes, not all of these are technically connectors… but for the sake of simplicity, we don’t care for this blog post). At the time of writing, the majority of people using the many other various types of disk connectors outside of the basics are generally going to be working within corporate enterprises which tend to operate on a bin and replace mentality from a hardware perspective for basic user computers and for data centres and server racks have setup with cloud native data storage with high availability and lots of redundancy. For many smaller organisations and/or personal use case, this is a goal to work towards.
Which is why we are covering this topic for the average user to help to understand the basics for how to clone a hard disk either if you are upgrading and/or are trying to recover data from a failing disk.
Adapters
Ok, so we’ve covered off the different types of hard disks, it’s time to look at how we connect them to a computer to perform the data migration. Here is where we need the correct connectors to do the job, and this isn’t straight forward.
For simplicity and ease, USB is likely to be the easiest solution for the majority of use cases. Note there is a significant difference in USB 1.0 VS USB 2.0 VS USB 3.0 when it comes to performance and to add to the complexity, there are also different USB Form Factors (aka. different shapes of the connector, but fundamentally doing the same thing) which adds to the confusion.
This is a complex topic, and one that quite frankly I don’t have the time to get into the details of – mainly because the manufacturers don’t make this easy and/or make this far more difficult than it should be. You see, we have things such as USB 1, 2, 3, SATA 1, 2, 3, IDE, 1, 2, 3 etc. and I just don’t have the mental capacity to care about too much the differences between these things. I work with what is available and adapt as needed.
The reality is that each and every connector or adapter has a maximum data transfer rate based on the physical materials and hardware that the device has been manufactured from. Everything has limitations and manufacturers don’t make this info easily accessible and/or understandable to the average joe.
Unique IDs of Disk Drives
Right, so now we’re onto the actual hard disk data migration. Now things get fun, and possibly dangerous – so be careful.
Almost every guide I’ve read online skims over this really important point, and it’s probably the most crucial point to take into account – which is to know your IDs, your Unique Hardware Identifier.
For a bit of background as it’s important to understand. For those with a software engineering and/or database background, you will be very familiar with a Unique Identifier for a ‘thing’. Well, with hardware manufacturing, they also do the same thing. For every physical chip that is manufactured, this is generally embedded with a hard coded unique identifier which both helps, and hinders, in many different ways, but that is a topic for another discussion. For example, the sensors that we use on the GeezerCloud product have a Unique ID for every single sensor that we use.
Anyhow, the most important aspect of what I want to mention for this blog post is that all disk drives have a unique identifier. Thankfully this identifier is printed on the physical disk that you have in front of you. It’s printed on the sticker that is physically attached to the disk.
Make a note of the ID of the Disks.
I cannot stress this enough. Make sure you have the IDs of the disks you are working with to transfer data from and to. Make a note of the labels printed on the physical disks so that you can ensure you are transferring data from the right source and to the correct destination.
There is no going back from an incorrect action at this step.
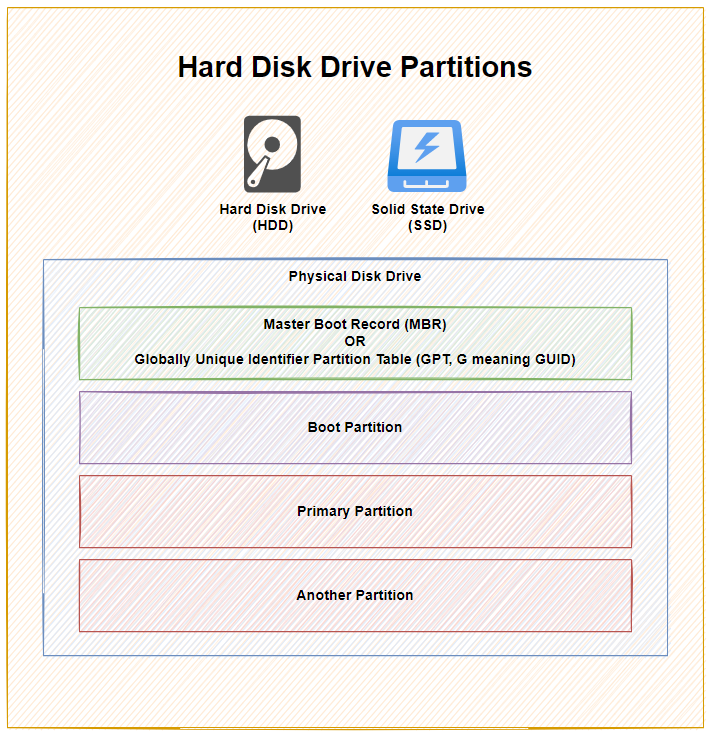
Physical Disks, Partitions and Bootable Disks
Next, before we actually get onto to the migration, it’s important to understand the context. There is a Physical Disk connected to the computer, but then we have Partitions and Boot Partitions to contend with along with both physical and logical volumes. Volumes is just another word for Partition.
This all depends on your specific use case. For example, if the disk you are cloning is from an external USB hard disk, then this probably doesn’t have a bootable operating system setup as it is just there to store basic data. Whereas if you are upgrading your primary disk that runs your operating system, then you will have a Boot Partition which is the part of the disk that runs a piece of software called the Boot Loader which is responsible for booting the operating system you have installed.
For Example;
As you can see above, with 1x physical disk drive, whether that is a Hard Disk Drive (HDD) or a Solid State Drive (SSD), they ultimately have the same bits under the hood to make the disk work as it should based on you requirements – either as a Bootable Disk or a Non-Bootable Disk.
To explain a few concepts;
The Master Boot Record (MBR) was for disks less than 2 TB in size. In reality these days, most disks are larger than 2 TB in size, so as a general rule of thumb, you are probably best always using Globally Unique Identifier Partition Table (GPT) when managing your disks. MBR has a maximum partition capacity of 2 TB, so even if your disk is 10 TB, the maximum size of any one partition is 2 TB, which soon becomes a pain to manage. Compared with GPT which has a maximum partition capacity of 9.4 ZB, so you’re good for a while using this option
Primary Partition, this is where your operating system is installed and your data saved
Another Partition, this is just an example where some people use multiple partitions on the disk to manage their data. In reality, for basic disks you are likely only using one primary partition for standard computer use. When you get into the world of Servers and Data Management, then you end up having many logical partitions to segment your data on the disk for the virtual machines using that data, but that’s out of scope of this blog post.
I have seen this a few times in practice when computers have come my way to fix after a ‘professional’ had already apparently fixed something and clearly it wasn’t done correctly. One recent example was with a 3 TB disk drive, yet only 2 TB of it was available for use as it had been configured with only one partition which had a maximum of 2 TB of size. Clearly the person setting this up didn’t really look too closely at anything they were doing, particularly as their primary ‘fix’ was to replace a 3 TB disk drive with a 120 GB disk drive, then the end person using the machine was sat wondering why nothing no-longer worked and the only way they could access their files was from an external USB drive. #FacePalm
Windows Disk Management
So what does all this look like in practice? Well, thankfully Windows 10 comes with a handy utility called Disk Management. To access this, simply right click on the Windows ‘Start Menu’ Icon and click on ‘Disk Management’.
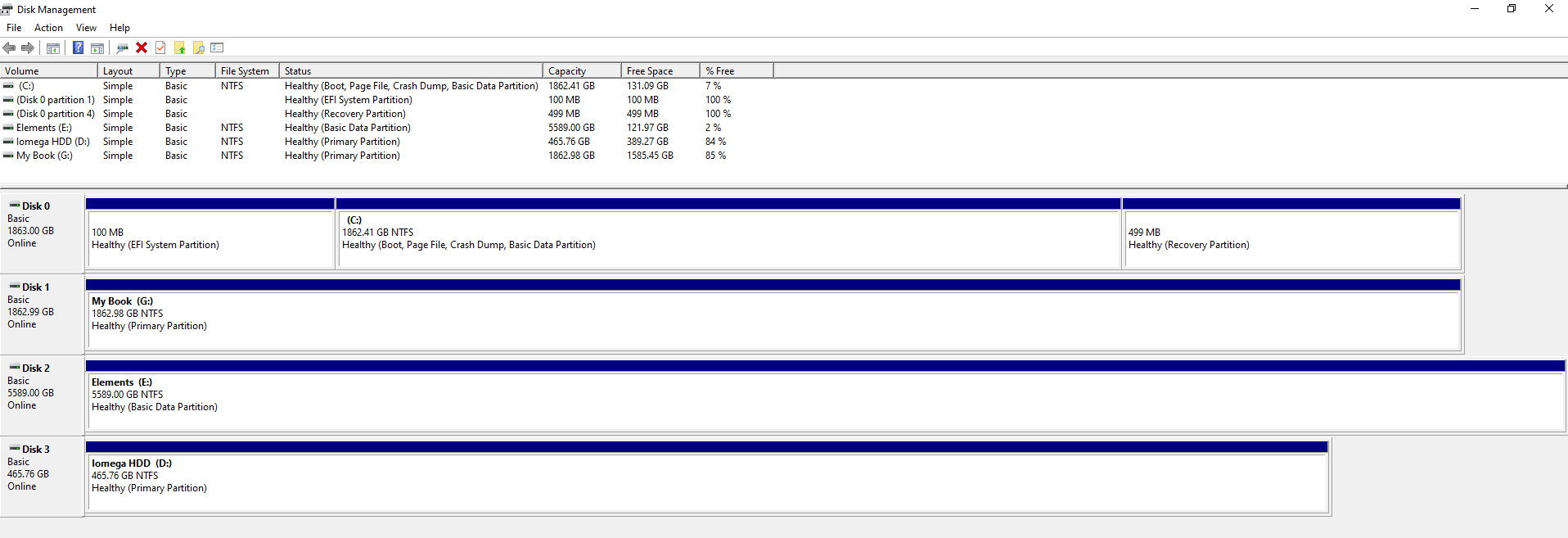
To bring the above conceptual diagram into focus, here is a real example of what this looks like with multiple disks to a computer;
In the above example you can see that there are 4x disks connected to the machine. One is the main disk used for the operating system and the other three are external USB hard drives in this example. What is a tad annoying with this user interface though is that it isn’t clear exactly which disk is which, so you have to be extremely careful. To any user Disk 0, 1, 2, 3 doesn’t really mean anything so at best you have to try and align the disk sizes to what you can see within your ‘This PC’ on your Windows machine.
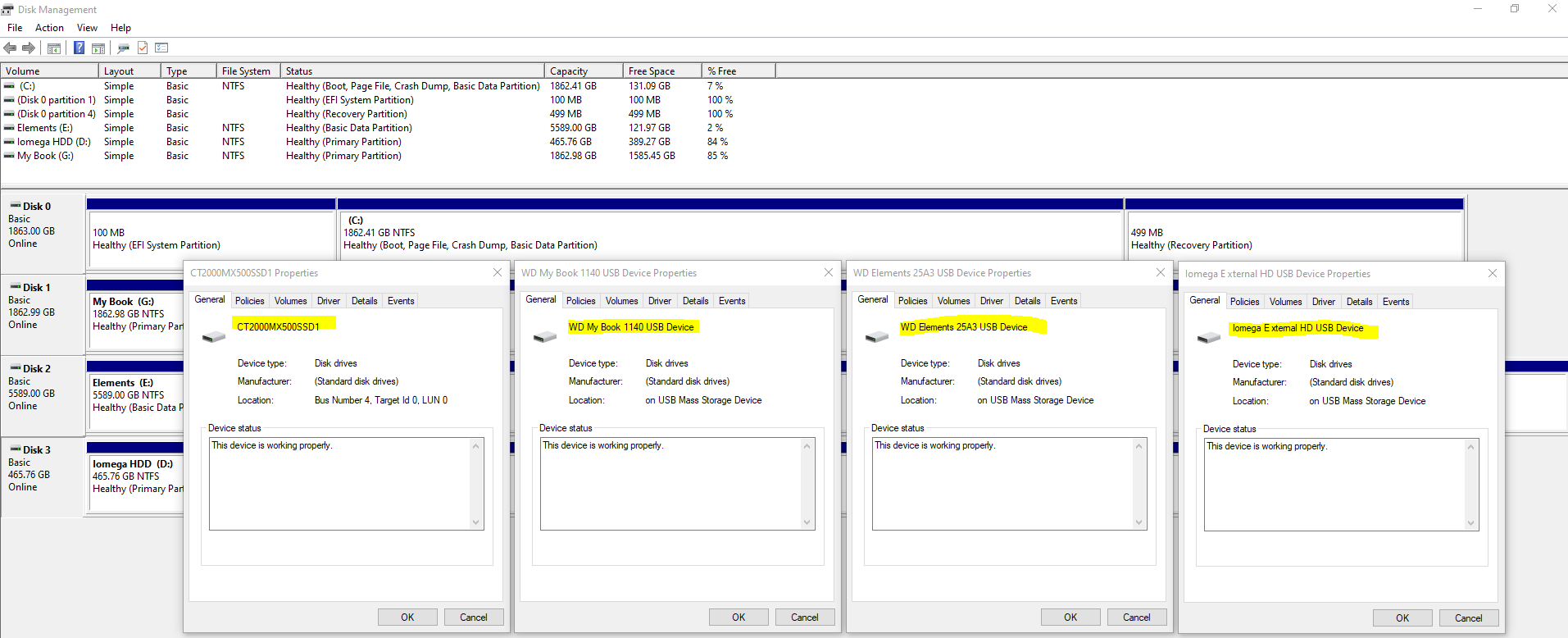
Thankfully when you Right Click on one of the rows and click on Properties, you can see the name of the disk come up as can be seen below;
This info will come in extremely handy when you start plugging in some disk drives that you are going to be working with. It’s essential that you are moving data from the correct disk to the correct disk.
Plugging in Your Disks
Ok, so now we’ve covered off the background topics for how to clone a hard disk, it’s time to jump in and give this a go. You must take this a step at a time to ensure you are 1000% confident that you are sure that you are doing the right thing. As I have said many times already, if you get this bit wrong, it’s going to be very disruptive – particularly if like many people you still don’t have 100% of your data backed up in the cloud.
So, here’s what you’re going to need;
Old Disk
New Disk (Contact us if you need us to supply and we can price things up if you aren’t sure what you’re looking for)
Make a note of the IDs of your disks from the labels on the physical disk drive. You should see these exact names show up in Windows Disk Management Utility Software. It is these IDs that you will need in the next step to make sure you are cloning the data from and to the correct disks.
One item to note is that if you are using a brand new disk for your New Disk, then you will need to Initialise the disk using GPT via Windows Disk Management Utility Software when prompted once it is plugged in. For disks that you are re-using then this initialisation step usually doesn’t appear. For new disks you will also need to right click on the unallocated area of the disk and select New Simple Volume, then give the Volume (aka. Partition) a size and a Drive Letter then you can format the new partition so you can use it going forwards. Then the drive is ready for use.
Clone Hard Disk Software
There is a small handful of software available both commercially and open source for cloning disk drives, with significantly varying usability aspects. For simplicity, we’re going to take a look at one of the easier to use pieces of software called Acronis True Image for Crucial.
Aconis is a commercial product, but many manufacturers have a free Clone Disk feature within Acronis, such as for Crucial Disk Drives the above software works. There are a lot of makes/models of disks on the market, so if in doubt about what software works best with your hardware, then contact the disk drive manufacturer directly via their support channels and they can advise best which software works best with your hardware.
There are also lots of super technical open source options available, but personally I’ve just not had time to play with these since this is fundamentally a basic copy and paste job fundamentally so it should have a user interface for allow anyone to do this kind of thing in my opinion.
Here are a few images of the setup I was playing with for the purpose of this blog post;
Open Up Clone Disk Tool in Acronis
When you have Acronis open, select the Clone Disk tool. Note, this can take a while to open up, so be patient.
Select Automatic Clone Mode
This is the mode that is most common to use which handles everything in the background for you. The Manual mode gives you much more control but can often be a bit overwhelming if you aren’t too familiar with some of these concepts.
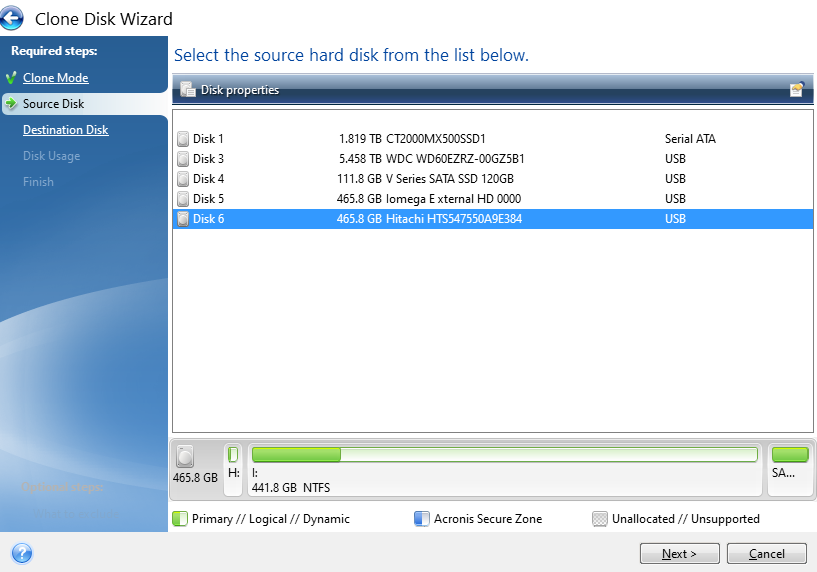
Select Source Disk
This step is particularly important, make sure you select the correct ID that is printed on the hard drive sticker so you are confident you are moving data from the correct disk drive.
You’ll notice the handy info that Acronis displays at the bottom which shows how the partitions on the drive are currently set up and what is and isn’t being used. This comes in very handy in the next step, particularly as in this case the data is being migrated from a 500 GB HDD to a 120 GB SSD. Your math is correct, that doesn’t fit – but – Acronis is smart enough to only transfer the data that is being used which means that in this scenario the data will fit.
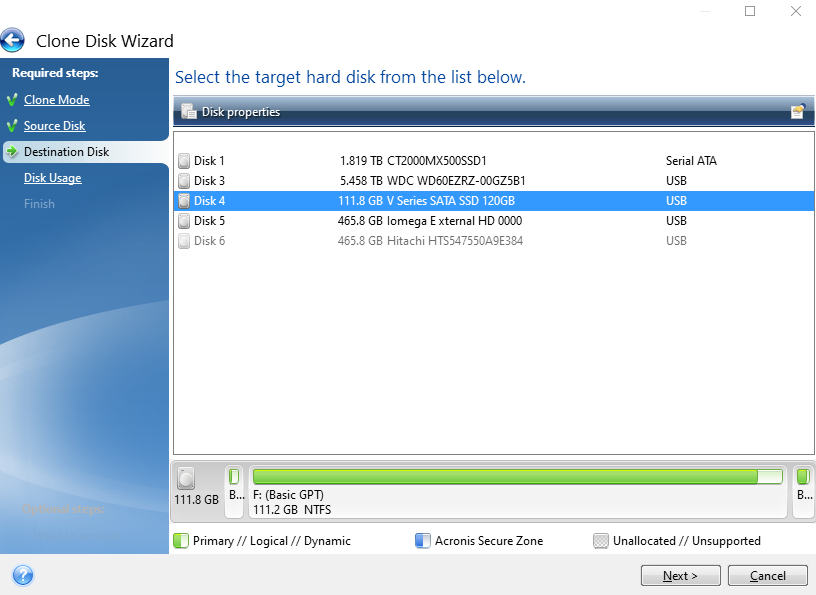
Select Destination Disk
Same as the previous step, make sure you are selecting the correct disk based on the IDs of the disk that is printed on your physical disk.
Select the Cloning Method
Next, select the cloning method you are doing. In my case both the old and new disks are connected via USB and are going to be used on another machine, not the machine that Acronis is installed and being run from. Generally speaking, when disk drives start failing, the machine they live in also becomes fairly unresponsive and/or just extremely sluggish. So it’s often easier to whip out the old disk drives and get them plugged into a decent computer that can do the grunt work.
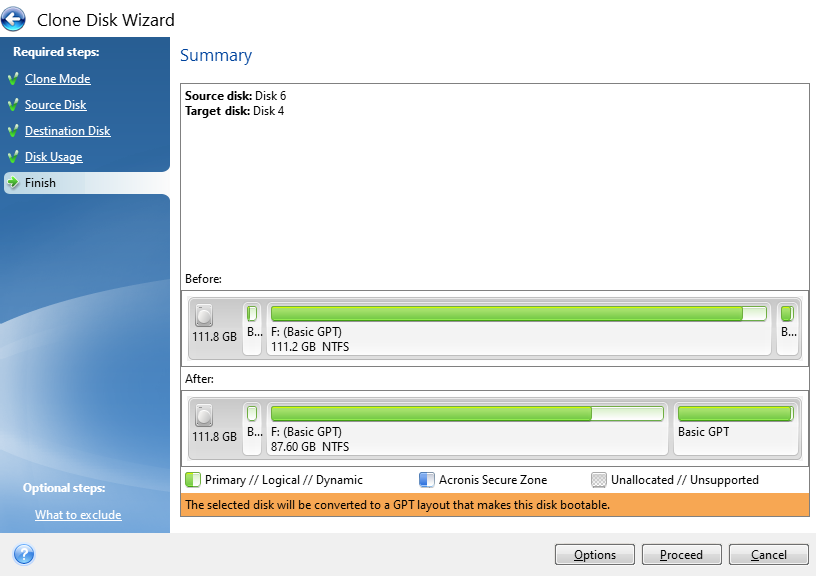
Confirm Settings and Start the Cloning Process
The final step is just confirming what your new disk will look like both at present and after the conversion process. In this example, this is an existing disk that is being flattened and re-purposed which is why the before info shows that the disk is full. If you are using a brand new disk, this will show up mainly empty as there will be nothing on it.
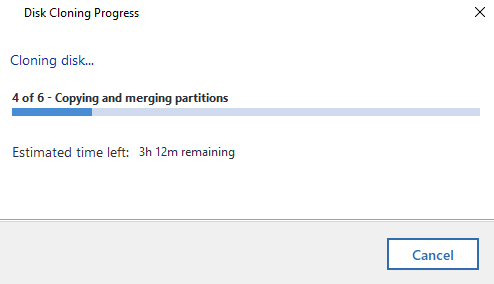
Now it’s just a case of sitting back and waiting. I’ve mentioned already Acronis is a slow piece of software for whatever reason. Just getting to this point probably took around 45 minutes believe it or not. The cloning process takes even longer. So make sure everything has plenty of juice to keep the power on throughout the process or you’ll end up losing a lot of time going through this process again.
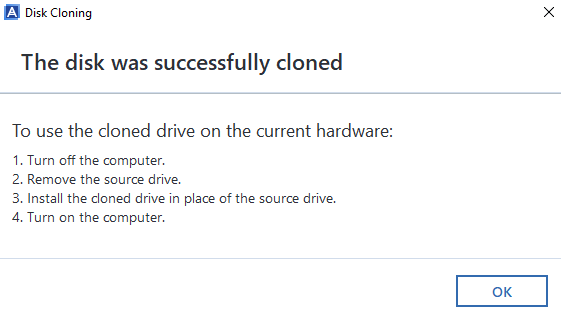
Disk Clone Successful
Woo! Finally, the cloning process has been complete. Now it’s just a case of plugging the new disk drive back into the computer you took the old one out of and everything should be back to normal, working fast again etc. If you do get any problems with this point, then generally the clone will have failed, even though Acronis says that it has worked. i.e. missing a bootable sector or some other form of corruption that is going to be near impossible to get to the bottom of.
Backups, Cloud, Redundancy Etc.
Ok, so we’ve run through the process of cloning hard disks either from HDD to HDD, HDD to SSD or SSD to SSD. Whatever your situation has been. What we haven’t covered off on this blog post yet is around backups, cloud and data redundancy etc. So let’s keep this topic really simple… your hard drives will fail at some point, so plan for it.
Use cloud service providers for storing your data, they have endless backups in place that are handled for you automatically without ever thinking about it. If you only have your data on your main hard disk in your computer, there is a chance that when your disk fails, you will permanently lose your data. Do not go backing up important data to external hard drives, this is manual, error prone and is still likely to result in some data loss for your data when one or more of your hard drives fail.
This is a topic that I could go into for a long time, but will avoid doing so within this blog post. Instead, let’s just keep things simple and ensure your data is backed up to the cloud. And make sure you can easily recover from a failed hard disk and be back up and running within hours, not weeks.
Notes on Failing Disks
Important to note that if you are working with a failing disk, then you can pretty much throw all of the above out of the window. Give it a go, but it’ll probably fail. You are probably best off getting a new disk drive and installing Windows 10 from scratch then you can copy the files over that you need (and backing them up to the cloud!). It’s a bit painful doing this but often it’s the only route when the disk drive has gone past the point of no return and is intermittently failing and doing random things. I’ve seen random things such as monitors flashing on/off with the Windows desktop going blank then back again on a repeat through to disk recovery software failing when it tries to read one single bit of data on the disk, usually about 95% into the process. It’s always best not to get to this point. Some other nuances I’ve seen is that BIOS wasn’t detecting the disk after an apparent successful clone, yet I could see the drive in Windows Device Manager when plugged into another machine, but it wasn’t showing up in Windows Disk Management. All very odd.
When thing get to this point, it’s time to just give up on the old disk, get Windows installed on a brand new one and salvage what you can. Learn your lesson and don’t make the same mistake twice. There are advanced recovery (and costly) options available to do deep dive recovery of data, which again on failing disks can even still be a bit hit and miss so you could be throwing good money after bad trying to recover this data, but it all depends on how important that data is to you.
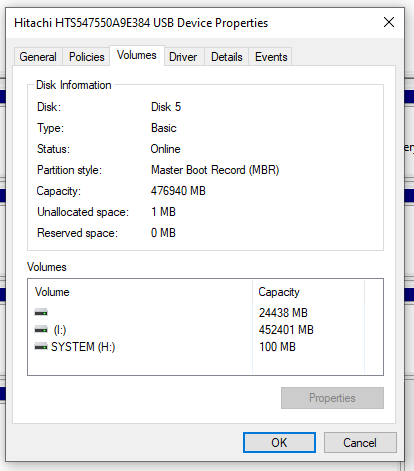
Check What Your Old Disk is Using – GPT or MBR
Something we didn’t go into in too much detail so far but is important to mention. GPT VS MBR – Make sure you check what the old disk is configured as. Or you’ll be repeating the processes again, or be forced to use a commercial bit of software to change GPT to MBR or the other way round. To do this, within Windows Disk Management, simply Right Click on the old drive and select Properties, then click on the Volumes tab where this info will be displayed. In this case we can see that the old drive is using MBR, so it’s best to configure the new disk drive also to use MBR because the computer this came from could (and likely will) have certain limitations at the BIOS layer about if MBR or GPT is supported (aka. UEIF Mode either Enabled or Disabled).
Note, Acronis is a pretty dumb and opinionated piece of software. It assumes that the Destination Disk Partition Mode (MBR VS GPT) is determined purely based on the computer that Acronis is running on. This is dumb, and quite frankly a fundamental flaw in the software in my opinion. In the vast majority of use cases in my experience, the Source Disk and Destination Disk are going to be plugged into an independent computer that is merely there to perform the copy and paste job.
MBR VS GPT is a Legacy VS Modern topic that is beyond the scope of this blog post. But what is important to note beyond the disk drive is that this comes down to the Motherboard’s BIOS Settings in relation to UEIF which is either Enabled or Disabled. Even still, there can be many compatibility issues in this space.
Sometimes, it’s just more effort than it is worth trying to upgrade a computer though. If it’s old, the Old HDD is old, then all the other components are old and slow. Sometimes it’s just more economic to throw away (recycle) the old and get a brand new computer and/or start with a fresh installation of Windows and go from there.
There are many bits of software that can help with cloning disks include: Clonezilla, Macrium Reflect Free, DriveImage XML, SuperDuper and many more. Many come with free basics and trial periods, but generally if you want to do something in full with an easy user experience, then you’re going to be using the commercial offerings.
After personally getting rather frustrated with Acronis, I decided to have a little rant on the Acronis Support Forums. Summary being “Unfortunately this is very unlikely to change for all users of Acronis True Image! This is because Acronis no longer support or develop this product.” And “The MVP community have been asking for this for some years but without any success.”. Not a very positive message, but at least an honest one from a senior member of the community given the lack of engagement from Acronis directly.
Summary
Hopefully this has been a helpful and detailed blog post for how to clone a hard disk drive (HDD) or solid state drive (SSD) and how you can handle this process for either failing disks or just upgrading disks to newer, faster and larger models.
Please take care when performing these actions and if you aren’t sure what you are doing, then leave this to the professionals. There are a lot of nuances with these types of actions which can be extremely destructive if you get this wrong. Be careful.
There are many ways to skin this cat, so this blog post is going to look at some of the ways that you can help simplify Apache Virtual Host configuration on Linux by breaking things down into manageable self-contained chunks with bounded contexts, aka. all around a domain name which is what 99% of people will be aiming to do.
The difficulty with the official documentation for Apache Virtual Hosts is that it provides many different examples to follow, but gives very little contextual information around use case and instead goes very deep into the art of the possible without guiding you to where you should look. And I guess that’s fine to an extent for official documentation, but it’s also not very useful at the same time as different configurations require different levels of complexity.
So in this blog post we’re going to focus on the common setup for what the majority of use cases for Apache Virtual Hosts are and how you should probably set this up to make your life easy.
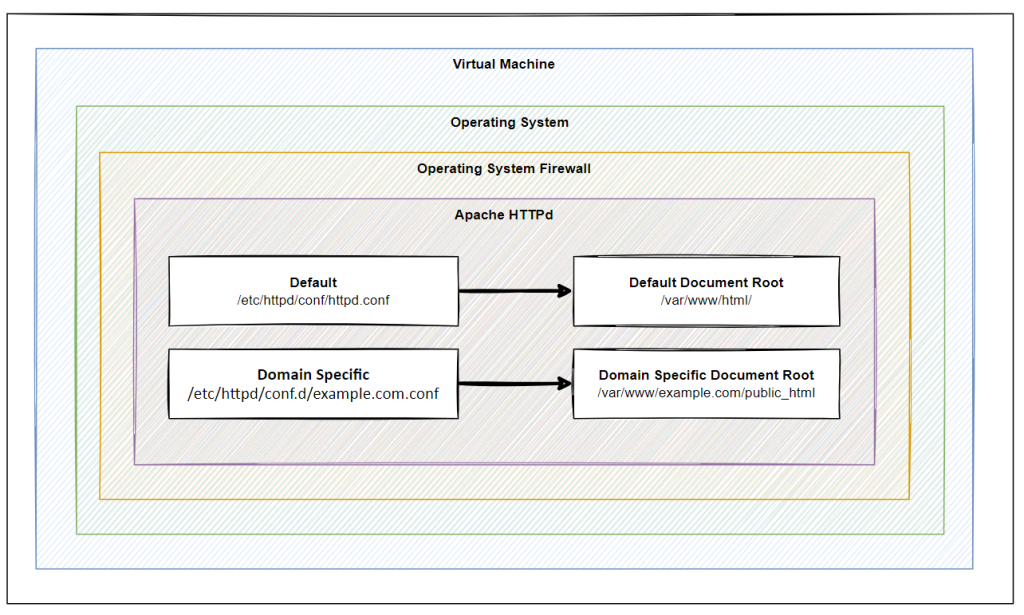
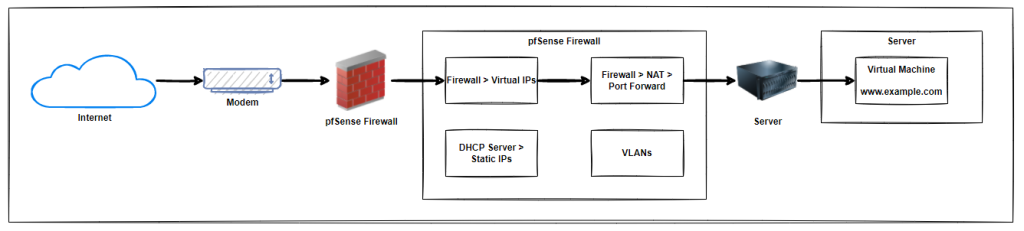
System Architecture
Firstly, it’s important to understand the situation we find ourselves in. Below is a basic hierarchy of layers where this sits. Naturally this is going to differ in reality for most situations, but conceptually in most cases, this tends to be the setup that is ultimately in place in one way or another with a few nuances along the way.
Virtual Machine
Operating
Firewall
Apache / HTTPd
Default
Default Document Root
Default httpd.conf
example.com
example.com Document Root
example.com httpd.conf
another-example.com
another-example.com Document Root
another-example.com httpd.conf
Operating System Firewall
Keep an eye on this, this is one of the steps that causes a lot of confusion. People often start working at the Apache HTTPd layer, yet haven’t opened the correct ports on the Operating System Firewall. By default many modern operating systems are out of the box configured as a deny-all setup so are likely to block traffic before it’s even reached your Apache HTTPd installation, usually the default open ports are only port 22 for SSH access.
Remember, the layers of your system are essential to understand in detail to make your life easier debugging problems.
The operating system firewall is beyond the scope of this blog post, so we’ll cover this off in a subsequent blog post, but always keep this in mind.
Apache HTTPd Installation
When we install Apache HTTPd via tools such as Yum it will create folders, files and scripts throughout the system. The important ones being;
/etc/httpd/ – For the configuration aspects of Apache HTTPd
/var/www/html – For the files that need to be served to users accessing web applications
This is the basics.
For single website hosting this can be more than fine to work with out of the box with zero additional configuration. In reality, most Apache HTTPd installations are hosting many websites, essentially acting as a mini-reverse proxy inside the virtual machine to host multiple websites on the same virtual machine and ultimately the same underlying infrastructure.
Document Roots
Ok, so getting back to basics here. What is a Document Root? In simple terms, this is the home directory for a specific configuration. To put this into context, most people run Windows computers for personal and corporate use. In this example, your “Document Root” is the equivalent of “My Documents”.
So when User 1 logs into a Windows computer they go to “My Documents” and see their own files.
When User 2 logs into a Windows computer they go to “My Documents” and see their own files.
The concept of a Document Root is essentially the under-the-hood configuration that makes this possible.
So in the same way when we are hosting multiple websites this essentially allows us to direct example-one.com to /example-one/index.html, and example-two.com to /example-two/index.html.
Conceptually this is what we’re working with, despite the terminology and underlying configurations being fairly complex using lots of terms that aren’t familiar to 99.9% of us and having to search the web to gather these pieces of information.
So, let’s dig deeper…
Default Document Root – /var/www/html
The default Document Root that is created on Apache HTTPd installation usually lives at /var/www/html. You can confirm this on first installation if you setup Apache HTTPd and then try to access the IP address of the virtual machine. If you have no advanced configuration sitting in the way, you’ll see a successful page that shows a message confirming that Apache HTTPd has been successfully installed. Awesome
Domain Specific Document Root – /var/www/example.com/public_html
But, what if you want to host multiple websites using Apache HTTPd, you need to segment this into a separate Document Root for ease of management. Essentially two separate folders for two different domains;
Create a basic “Hello World” index.html file for Example One and Example Two so you can easily identify the two and you’re good to go.
You’ll notice that if you check these locations after initial setup that they don’t exist. You need to create these folders and files using Linux commands such as mkdir and nano index.html if you’re not too familiar with these commands. These commands are the equivalent on Windows of right clicking and selecting the Create Folder menu item and the Create File item respectively.
Here we have now created two separate folders, aka. Document Roots, that we can then use to configure the Apache HTTPd Configuration.
Apache HTTPd Configuration Files
Now that we’ve covered off the Document Roots which is where your files live, the next step is to cover off how to configure Apache HTTPd Virtual Hosts properly to ensure your hostnames can root to the correct Document Root.
Default HTTPd.conf – /etc/httpd/conf/httpd.conf
The default configuration file that comes out of the box with Apache HTTPd is located at /etc/httpd/conf/httpd.conf. This is the global single file that rules them all. What is important though is that this file can be added to and also extended or overridden. This is where things get interesting.
There are many way to skin a cat, and this is one example. Fundamentally there are two ways to extend the Apache HTTPd configuration, one of them is by extending this main configuration file. The other is what we’re going to cover off next.
While is it possible to extend the main Apache httpd.conf file, it’s generally bad practice to do so when you are configuring virtual hosts. Mainly because it makes things significantly more difficult to manage and maintain.
If you do want to add Virtual Hosts configuration to the primary httpd.conf file then you simply add these details;
Ultimately though, whatever you do in your httpd.conf file, can be over ruled by a separate domain specific configuration file. This is what we’re going to cover next.
It’s not best practice to add Virtual Hosts to your httpd.conf file as it keeps every single configuration bound to a single file which can cause problems with dependencies over time.
Domain Specific HTTPd.conf – /etc/httpd/conf.d/example.com.conf
So we’ve talked previously about adding the specific configuration to a separate Apache HTTPd configuration file which is what we’re going to look at next. Apache is a well-established and advanced piece of software which understands parent/child relationships. And this is the case with .conf files.
As we’ve seen earlier around how the core httpd.conf file is located and how the override is configured, let’s look at this;
/etc/httpd/conf.d/example.com.conf – Domain specific Apache HTTPD configuration file
It’s not super complex in practice, while under the hood it clearly is. Ultimately it’s a simple scenario that if there is a domain specific configuration file then this takes priority over the general configuration file.
And all this is managed through the configuration of the Apache HTTPd Virtual Hosts syntax.
To manage this effectively, simply create a file using the command;
nano /etc/httpd/conf.d/example.com.conf
Then add in the exact same configuration details that we’ve outlined earlier;
What this essentially means is that Apache will take into account these additional configuration files and use them to override the default. This is all accomplished via the primary http.conf file mentioned earlier with the out of the box configuration of;
IncludeOptional conf.d/*.conf
There is nothing specific to configure to make sure this is working.
Virtual Machine or Apache Level SSL Configuration via Let’s Encrypt
There are many way to ‘do’ SSL. In most legacy on-prem setups, you’ll tend to find that SSL is offloaded at the primary on-prem firewall and traffic is unencrypted from that point forward as traffic travels to the correct virtual machine with Apache or Nginx is running etc.
I’m not saying this is bad practice per say, because it works, but yeah, it’s often a very error prone setup with all eggs in one basket and all and often causes significant bottle necks as the primary firewall tends to be heavily restricted and any change is virtually impossible to make without weeks of discussions, planning, forms and more – for what is ultimately a 5 minute job in most cases to implement.
So, for the purpose of this blog post and to provide a full end to end setup, we’re going to assume that you’re using modern Let’s Encrypt technologies to generate your SSL certificates on the fly for free every few months automatically, from the virtual machine where your application lives.
If you need more information about Let’s Encrypt then we have covered off several blog posts on this topic over the years so search around the site, some of the core ones being;
Why it’s important to mention this is because of the previous setups we’ve gone through.
Security Considerations
We’ve not really covered security considerations for any of the above in this blog post as this is a significantly more in-depth discussion which has many nuances based on every individual setup, governance and controls.
For the purpose of this blog post, this has been to look at how to host multiple websites behind a properly configured Apache HTTPd Virtual Host setup for applications that you own, control and can trust 100%.
Things get significantly more complex for other applications when there are multi-tenancy considerations which is ultimately where software such as cPanel and WHM come into play, but that’s a topic for another time.
Summary
Hopefully this blog post has provided you with some insight on how to configure Apache Virtual Hosts using Document Roots and HTTPd.conf files and separate domain specific HTTPd configuration files to help make your life easy to manage and keep configurations segmented.
As with everything Apache and HTTPd related, everything is going to be specific to your individual use case so please treat this blog post as guidance not a rule. Take a look at your own set up and assess how any of this information may or may not apply to your specific setup.
I’ve found that this topic is quite an undocumented one online and lots of assumptions tend to be made. The majority of content online under this topic that I’ve come across tends to direct you down the route of HA Proxy, which can be fine with very specific setups. But, the minute you want to start to do anything more complex than the basics, HA Proxy soon becomes limiting.
Many websites these days have multiple ports open for specific use cases. Take for example one of the most common web hosting platforms cPanel, this requires many open inbound ports at the firewall layer and in other scenarios we want to give the control to the virtual machine’s operating system the power to decide what ports to allow in without having to configure the firewall every time since they may not have access to the firewall.
We did a blog post recently for How to Setup HA Proxy on pfSense to Host Multiple Websites, which is worth a read to understand the differences for what we are going to cover off here. The core difference here is that with HA Proxy, you have to be explicit when configuring it which ties the settings against a single port, which often is too limiting for many applications.
To get the maximum flexibility you need multiple public IP addresses. This allows you to configure things in any way that you require. So this is what we’re going to cover off in this blog post.
System Architecture
To get a high level view of a setup like this we have the basic components that are outlined below. With a modem, connected to a pfSense firewall which has virtual IP addresses, port forwarding, static IP addresses for virtual machines, VLANs for security configured, then connected to a server with a virtual machine running on it.
In reality, there are often a few bits more along the way and significantly more complex in real world environments, but fundamentally, this is the basic architecture for how all this plugs together.
Purchase Additional Public IP Addresses from your ISP
Firstly, you need to purchase a block of IP addresses from your internet provider. What happens when you do this is that any traffic from those public IP address ranges will ultimately route through to your pfSense firewall so you can then determine what happens to that traffic next.
We’ve covered off a blog post a while ago which helps you to Understand Network Private Address Ranges and looks at the difference between public IP address ranges and private IP address ranges. So take a look at that blog post if you aren’t sure of the difference.
Ok, so now you’ve got your additional public IP addresses.
pfSense Firewall Virtual IP Address Configuration
Now it’s time to tell your pfSense firewall about these IP addresses so it knows how to handle the traffic that is coming in. The first step is to setup Virtual IP addresses within pfSense. To do this, simple navigate to Firewall > Virtual IPs.
There is nothing particularly complex for settings these up. Simple setup the type as an IP Alias, the interface would be the WAN, the Addresses would be one of the IP addresses with the /32 CIDR range (aka. single IP address), then give it a friendly name and you’re done.
Configure NAT Port Forwarding Rules in pfSense
Now that we’ve got the Virtual IPs configured, it’s time to configure the port forwarding rules so the traffic gets to where it needs to for that public IP address. To get started with this, simply navigate to Firewall > NAT > Port Forward. Then add in some rules.
As you can see in the screenshot below, the settings are rather basic, with the rule being applied to the WAN interface, for the TCP protocol where the Destination Address is the Public IP Address that you added as a Virtual IP Address previously, then forwarding traffic to the static IP address of the virtual machine whenever traffic is received on any port.
When you do this, pfSense will automatically add a Firewall Rule on the WAN interface.
pfSense Static IPs and VLANs
We’re not going to cover this off within this blog post as this is a separate topic and one that is going to be dependent on your specific setup. The static IP addresses are important to ensure your Virtual Machines always get the same IP address every time they are rebooted so that the firewall rules are still accurate.
Likewise, the VLANs and IP ranges are extremely important from a security perspective to ensure that any inbound traffic is securely segmented from your sensitive internal systems and/or other separate public IP ranges that need to be kept separate from other ones.
Server and Virtual Machines
To keep this bit relatively short and simple, if you have configured all of the above correctly, the traffic that comes into your WAN from specific IP addresses then this will flow through to your virtual machine that you have setup.
So for example, if you have the DNS A Record setup for mk1.contrado.cloud as 62.3.66.193, then this traffic will reach the specific virtual machine where the operating system firewall will then control what traffic it will accept in and what traffic it will deny.
This setup gives you the complete control of the traffic without having to continually play with the pfSense firewall rules.
Summary
Hopefully the above is a handy guide for how to configure pfSense with multiple public IP addresses then use NAT so that you can host multiple websites using multiple ports with minimal configuration within the pfSense firewall.
This is a complex topic, and one that is going to be very different in every single use case. Hopefully this blog post had helped fill in a few gaps in knowledge to get you pointed in the right direction.