This is a fairly common issue that happens randomly on WordPress websites which has the catastrophic impact of bringing the entire website offline resulting in users seeing the error whenever they try and load a page on the website.
This can feel quite daunting when you first see this error, but don’t worry as there is a methodical process to solving this issue. As with many things with WordPress, there are many different root causes of these kinds of issues, so it’s simply a case of debugging things to identify what is causing the issue which will allow you to identify the next steps to solve the issue.
The common root causes of the “Error establishing a database connection” on WordPress can be;
Incorrect database connection details in your /wp-config.php file (unlikely if you haven’t actively changed this recently – more common for new manual installations of WordPress)
Corrupt Plugin files which can often occur after recent updates to Plugins
Corrupt database table(s) which need repairing
So let’s look at how to debug each of the common problems.
Check Database Connection Details
Simply open your /wp-config.php file and confirm that the details are correct for the following settings;
define(‘DB_NAME’, ‘your_database_name’);
define(‘DB_USER’, ‘your_database_username’);
define(‘DB_PASSWORD’, ‘your_database_password’);
define(‘DB_HOST’, ‘localhost’);
Unless you’ve recently changed these settings between the last time the website was working and the time you are seeing the “Error establishing a database connection” error appeared, then it is unlikely that this is the root cause of the issue.
Check for Corrupt Plugin Files
Whether you are manually updating your Plugins or you have these configured to automatically update (which is highly recommended) both failed or successful Plugin updates can result in this error showing. To quickly debug this, simply rename the /wp-content/plugins folder to /wp-content/plugins-disabled
When WordPress cannot find a Plugins folder it simply disables all plugins from running whenever you load a page on your website. So this is a quick test where you can simply rename the folder, then try refreshing the website again to see if the error has disappeared.
If that has solved the problem, then you simply need to rename the folder back to it’s original name, then methodically disable one plugin at a time by repeating that same process on the sub-folders for the individual Plugins to determine which plugin is causing the issue.
Repair Corrupt Database Tables
This one is a little more challenging to debug manually, but thankfully recent versions of WordPress have a handy tool to identify issues and try and automatically fix the problem.
Firstly, you need to edit your wp-config.php file and add the following line in;
define(‘WP_ALLOW_REPAIR’, true);
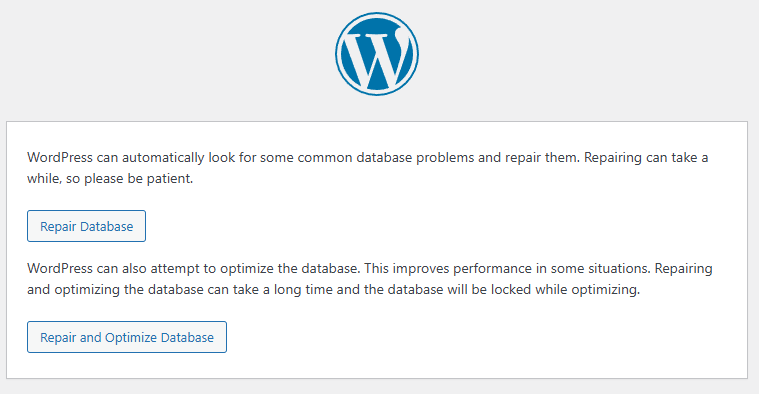
Once that setting is turned on, you can visit https://example.com/wp-admin/maint/repair.php (naturally replacing the domain name with the one you are working on)
You may see a page similar to the above or one full of errors and database tables – either way, you will see the options to either;
Repair Database
Repair and Optimize Database
So give those a go.
All being well, this will solve the issue and your website will be back online.
There are also a few other handy debugging steps related to this such as if you’re running phpMyAdmin then you will probably notice that the table appears locked and will often say that the table is “in use” which is a strong indicator that there is an issue.
It is possible to fix this issue via phpMyAdmin by selecting the table and selecting the option to Repair Table which effectively does the same thing the above automated process has done.
And if you’re running on cPanel, then it’s handy to view the cPanel error log for the specific cPanel account by running the command via SSH;
cd /home/cpanel-account-username/public_html
tail error_log
Which will output any errors that the site is having. It’s important to note that for this step to work, you must have your WordPress error logs turned on in your wp-config.php file and must have loaded the page again so the errors actually get written to the log.
This is a topic that comes up quite infrequently for many people and for most, never. It’s also one of the topics that is significantly more complex than it should be and one that is fairly poorly documented online about how to do this properly. Fundamentally this is a basic Copy & Paste exercise at best, but it’s made ridiculously complex by the underlying technical gubbins. So hopefully this blog post can clear up the steps involved and some of the considerations you need to make.
Old and New Disks
Disks come in many different shapes and sizes both conceptually and physically, with varying connectors and different underlying technologies. The nuances of these are beyond the scope of this blog post, but to put a few basics down to help conversation let’s look at a few of these at a high level.
We’ve previously covered off topics on the Performance of SSDs VS HDDs so take a look at that for some handy background info.
Summary being that you essentially have two types of hard drives;
Mechanical Hard Disk Drive (HDD) – Has moving parts
Solid State Drives (SSD) – Has no moving parts
See the above blog post for further insights into the differences.
Anyhow, the important point being for the purpose of cloning a hard disk is that you need to know the details of what you are going from and what you are moving to. Get this wrong and you can seriously mess things up in a completely un-recoverable way, so please be careful and if you aren’t sure what you are doing, don’t proceed and instead pass this onto a professional to do this for you.
Disk Connectors – IDE VS SATA
For the sake of simplicity, the two core connectors for disk drives fundamentally fall into either IDE (old) and SATA (new). Yes, the teckies who are reading this will say that this is garbage, and it is. But, in reality, for those reading this blog post, this is likely going to cover 99% of the use case.
In reality there are many types of disk connectors from PATA, SATA, SCSI, SSD, HDD, IDE, M.2 NVMe. M.2 SATA, mSATA, RAID, Host Bus Adapters (HBA) and more (and yes, not all of these are technically connectors… but for the sake of simplicity, we don’t care for this blog post). At the time of writing, the majority of people using the many other various types of disk connectors outside of the basics are generally going to be working within corporate enterprises which tend to operate on a bin and replace mentality from a hardware perspective for basic user computers and for data centres and server racks have setup with cloud native data storage with high availability and lots of redundancy. For many smaller organisations and/or personal use case, this is a goal to work towards.
Which is why we are covering this topic for the average user to help to understand the basics for how to clone a hard disk either if you are upgrading and/or are trying to recover data from a failing disk.
Adapters
Ok, so we’ve covered off the different types of hard disks, it’s time to look at how we connect them to a computer to perform the data migration. Here is where we need the correct connectors to do the job, and this isn’t straight forward.
For simplicity and ease, USB is likely to be the easiest solution for the majority of use cases. Note there is a significant difference in USB 1.0 VS USB 2.0 VS USB 3.0 when it comes to performance and to add to the complexity, there are also different USB Form Factors (aka. different shapes of the connector, but fundamentally doing the same thing) which adds to the confusion.
This is a complex topic, and one that quite frankly I don’t have the time to get into the details of – mainly because the manufacturers don’t make this easy and/or make this far more difficult than it should be. You see, we have things such as USB 1, 2, 3, SATA 1, 2, 3, IDE, 1, 2, 3 etc. and I just don’t have the mental capacity to care about too much the differences between these things. I work with what is available and adapt as needed.
The reality is that each and every connector or adapter has a maximum data transfer rate based on the physical materials and hardware that the device has been manufactured from. Everything has limitations and manufacturers don’t make this info easily accessible and/or understandable to the average joe.
Unique IDs of Disk Drives
Right, so now we’re onto the actual hard disk data migration. Now things get fun, and possibly dangerous – so be careful.
Almost every guide I’ve read online skims over this really important point, and it’s probably the most crucial point to take into account – which is to know your IDs, your Unique Hardware Identifier.
For a bit of background as it’s important to understand. For those with a software engineering and/or database background, you will be very familiar with a Unique Identifier for a ‘thing’. Well, with hardware manufacturing, they also do the same thing. For every physical chip that is manufactured, this is generally embedded with a hard coded unique identifier which both helps, and hinders, in many different ways, but that is a topic for another discussion. For example, the sensors that we use on the GeezerCloud product have a Unique ID for every single sensor that we use.
Anyhow, the most important aspect of what I want to mention for this blog post is that all disk drives have a unique identifier. Thankfully this identifier is printed on the physical disk that you have in front of you. It’s printed on the sticker that is physically attached to the disk.
Make a note of the ID of the Disks.
I cannot stress this enough. Make sure you have the IDs of the disks you are working with to transfer data from and to. Make a note of the labels printed on the physical disks so that you can ensure you are transferring data from the right source and to the correct destination.
There is no going back from an incorrect action at this step.
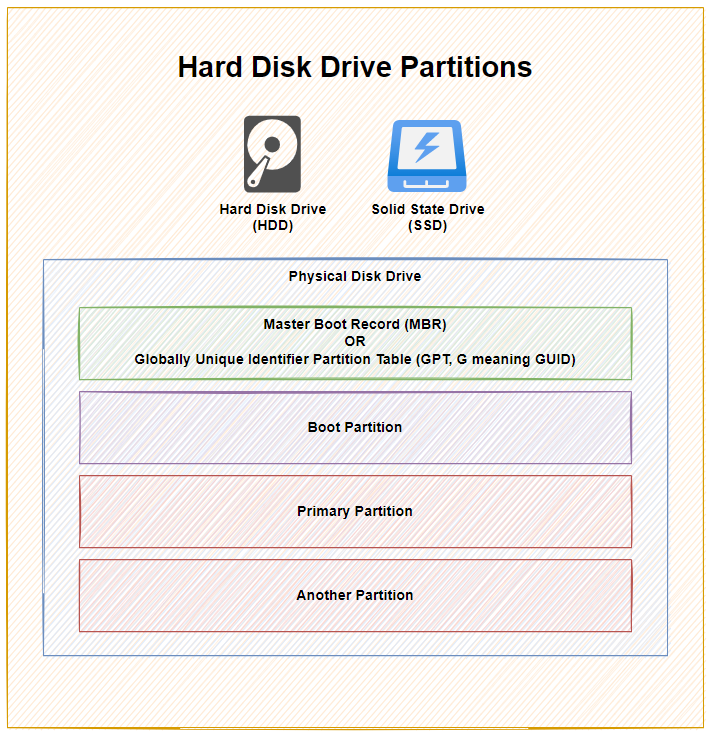
Physical Disks, Partitions and Bootable Disks
Next, before we actually get onto to the migration, it’s important to understand the context. There is a Physical Disk connected to the computer, but then we have Partitions and Boot Partitions to contend with along with both physical and logical volumes. Volumes is just another word for Partition.
This all depends on your specific use case. For example, if the disk you are cloning is from an external USB hard disk, then this probably doesn’t have a bootable operating system setup as it is just there to store basic data. Whereas if you are upgrading your primary disk that runs your operating system, then you will have a Boot Partition which is the part of the disk that runs a piece of software called the Boot Loader which is responsible for booting the operating system you have installed.
For Example;
As you can see above, with 1x physical disk drive, whether that is a Hard Disk Drive (HDD) or a Solid State Drive (SSD), they ultimately have the same bits under the hood to make the disk work as it should based on you requirements – either as a Bootable Disk or a Non-Bootable Disk.
To explain a few concepts;
The Master Boot Record (MBR) was for disks less than 2 TB in size. In reality these days, most disks are larger than 2 TB in size, so as a general rule of thumb, you are probably best always using Globally Unique Identifier Partition Table (GPT) when managing your disks. MBR has a maximum partition capacity of 2 TB, so even if your disk is 10 TB, the maximum size of any one partition is 2 TB, which soon becomes a pain to manage. Compared with GPT which has a maximum partition capacity of 9.4 ZB, so you’re good for a while using this option
Primary Partition, this is where your operating system is installed and your data saved
Another Partition, this is just an example where some people use multiple partitions on the disk to manage their data. In reality, for basic disks you are likely only using one primary partition for standard computer use. When you get into the world of Servers and Data Management, then you end up having many logical partitions to segment your data on the disk for the virtual machines using that data, but that’s out of scope of this blog post.
I have seen this a few times in practice when computers have come my way to fix after a ‘professional’ had already apparently fixed something and clearly it wasn’t done correctly. One recent example was with a 3 TB disk drive, yet only 2 TB of it was available for use as it had been configured with only one partition which had a maximum of 2 TB of size. Clearly the person setting this up didn’t really look too closely at anything they were doing, particularly as their primary ‘fix’ was to replace a 3 TB disk drive with a 120 GB disk drive, then the end person using the machine was sat wondering why nothing no-longer worked and the only way they could access their files was from an external USB drive. #FacePalm
Windows Disk Management
So what does all this look like in practice? Well, thankfully Windows 10 comes with a handy utility called Disk Management. To access this, simply right click on the Windows ‘Start Menu’ Icon and click on ‘Disk Management’.
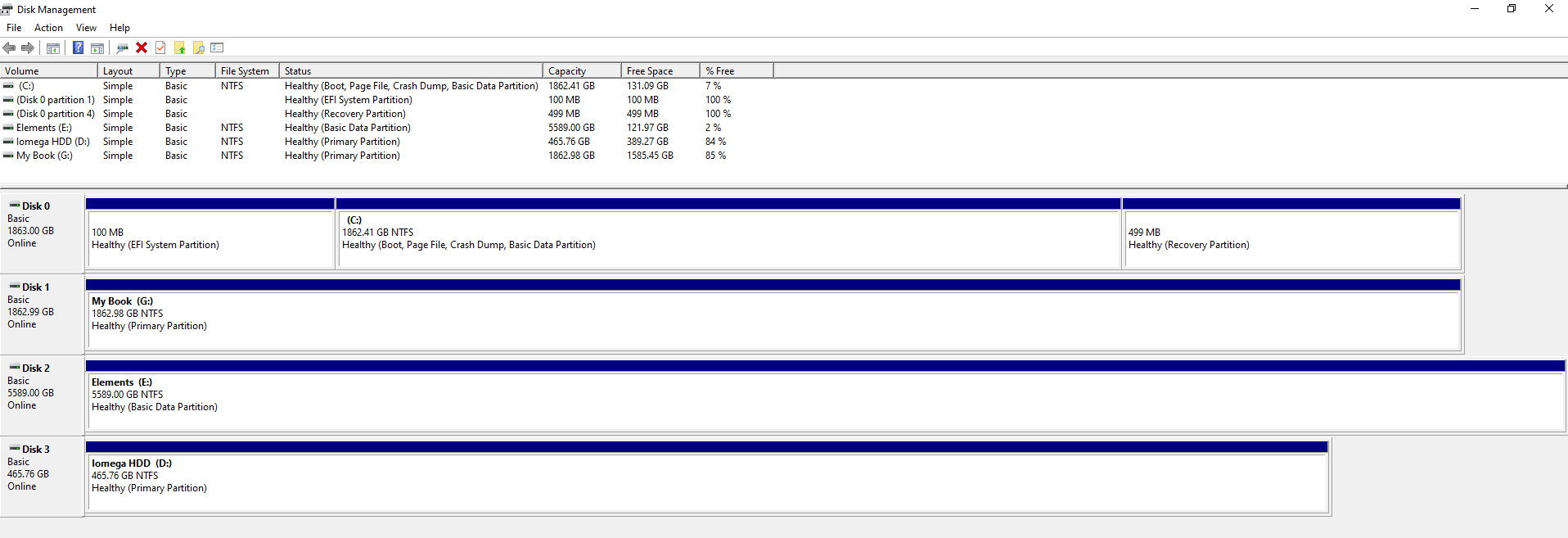
To bring the above conceptual diagram into focus, here is a real example of what this looks like with multiple disks to a computer;
In the above example you can see that there are 4x disks connected to the machine. One is the main disk used for the operating system and the other three are external USB hard drives in this example. What is a tad annoying with this user interface though is that it isn’t clear exactly which disk is which, so you have to be extremely careful. To any user Disk 0, 1, 2, 3 doesn’t really mean anything so at best you have to try and align the disk sizes to what you can see within your ‘This PC’ on your Windows machine.
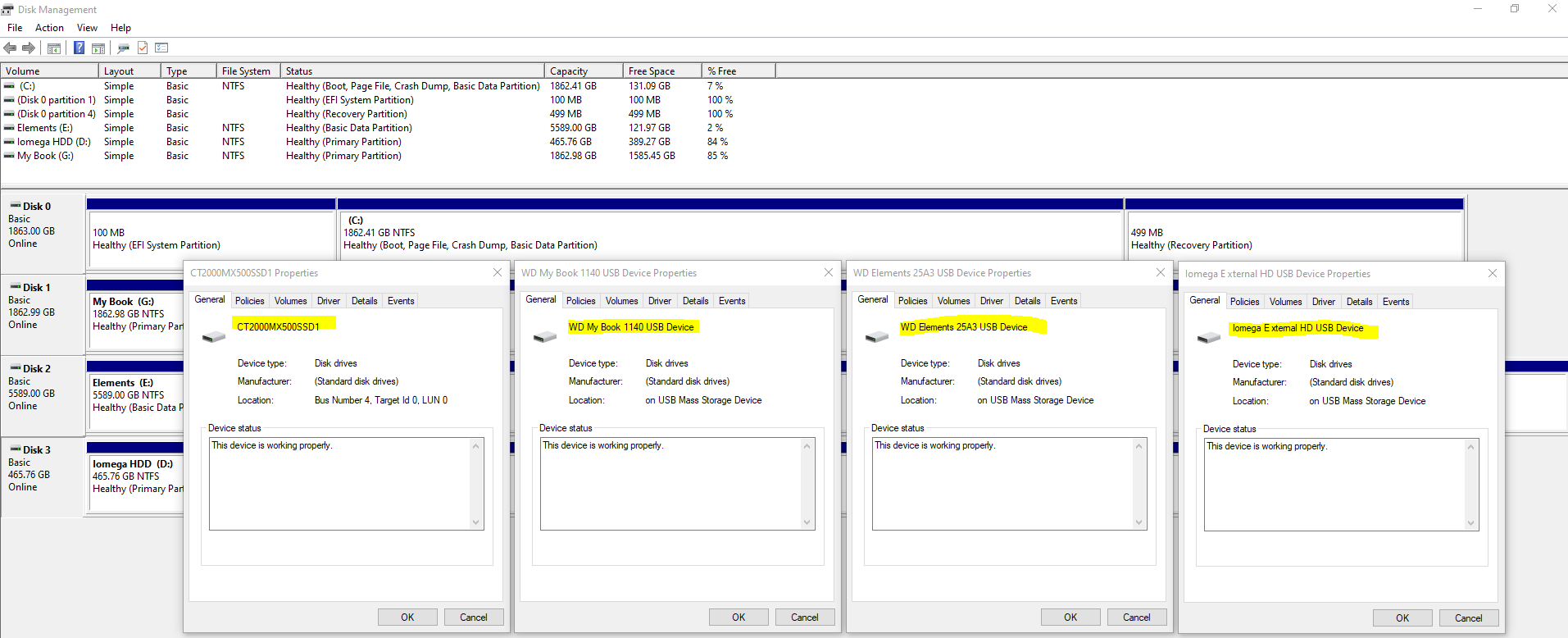
Thankfully when you Right Click on one of the rows and click on Properties, you can see the name of the disk come up as can be seen below;
This info will come in extremely handy when you start plugging in some disk drives that you are going to be working with. It’s essential that you are moving data from the correct disk to the correct disk.
Plugging in Your Disks
Ok, so now we’ve covered off the background topics for how to clone a hard disk, it’s time to jump in and give this a go. You must take this a step at a time to ensure you are 1000% confident that you are sure that you are doing the right thing. As I have said many times already, if you get this bit wrong, it’s going to be very disruptive – particularly if like many people you still don’t have 100% of your data backed up in the cloud.
So, here’s what you’re going to need;
Old Disk
New Disk (Contact us if you need us to supply and we can price things up if you aren’t sure what you’re looking for)
Make a note of the IDs of your disks from the labels on the physical disk drive. You should see these exact names show up in Windows Disk Management Utility Software. It is these IDs that you will need in the next step to make sure you are cloning the data from and to the correct disks.
One item to note is that if you are using a brand new disk for your New Disk, then you will need to Initialise the disk using GPT via Windows Disk Management Utility Software when prompted once it is plugged in. For disks that you are re-using then this initialisation step usually doesn’t appear. For new disks you will also need to right click on the unallocated area of the disk and select New Simple Volume, then give the Volume (aka. Partition) a size and a Drive Letter then you can format the new partition so you can use it going forwards. Then the drive is ready for use.
Clone Hard Disk Software
There is a small handful of software available both commercially and open source for cloning disk drives, with significantly varying usability aspects. For simplicity, we’re going to take a look at one of the easier to use pieces of software called Acronis True Image for Crucial.
Aconis is a commercial product, but many manufacturers have a free Clone Disk feature within Acronis, such as for Crucial Disk Drives the above software works. There are a lot of makes/models of disks on the market, so if in doubt about what software works best with your hardware, then contact the disk drive manufacturer directly via their support channels and they can advise best which software works best with your hardware.
There are also lots of super technical open source options available, but personally I’ve just not had time to play with these since this is fundamentally a basic copy and paste job fundamentally so it should have a user interface for allow anyone to do this kind of thing in my opinion.
Here are a few images of the setup I was playing with for the purpose of this blog post;
Open Up Clone Disk Tool in Acronis
When you have Acronis open, select the Clone Disk tool. Note, this can take a while to open up, so be patient.
Select Automatic Clone Mode
This is the mode that is most common to use which handles everything in the background for you. The Manual mode gives you much more control but can often be a bit overwhelming if you aren’t too familiar with some of these concepts.
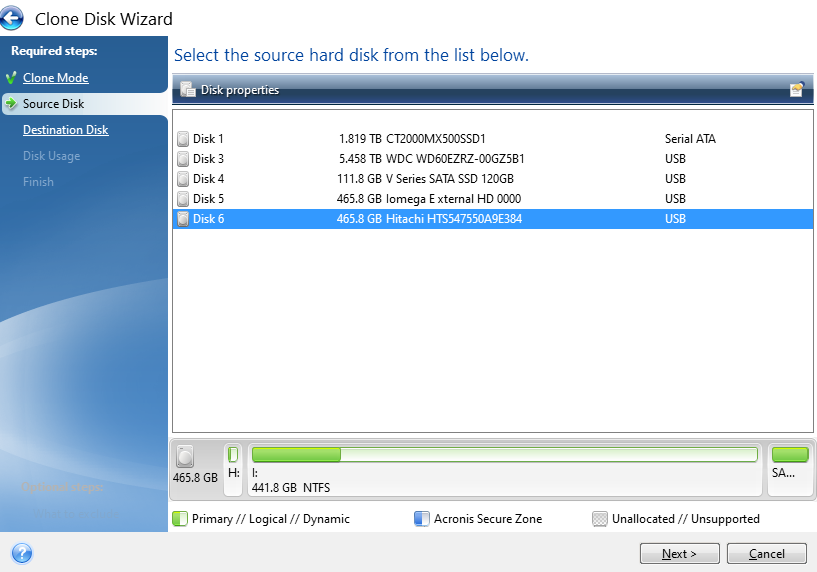
Select Source Disk
This step is particularly important, make sure you select the correct ID that is printed on the hard drive sticker so you are confident you are moving data from the correct disk drive.
You’ll notice the handy info that Acronis displays at the bottom which shows how the partitions on the drive are currently set up and what is and isn’t being used. This comes in very handy in the next step, particularly as in this case the data is being migrated from a 500 GB HDD to a 120 GB SSD. Your math is correct, that doesn’t fit – but – Acronis is smart enough to only transfer the data that is being used which means that in this scenario the data will fit.
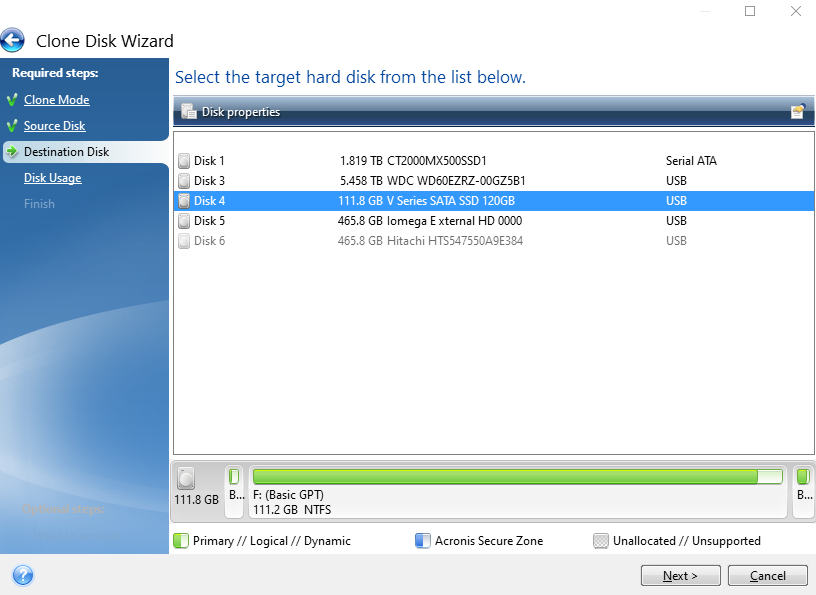
Select Destination Disk
Same as the previous step, make sure you are selecting the correct disk based on the IDs of the disk that is printed on your physical disk.
Select the Cloning Method
Next, select the cloning method you are doing. In my case both the old and new disks are connected via USB and are going to be used on another machine, not the machine that Acronis is installed and being run from. Generally speaking, when disk drives start failing, the machine they live in also becomes fairly unresponsive and/or just extremely sluggish. So it’s often easier to whip out the old disk drives and get them plugged into a decent computer that can do the grunt work.
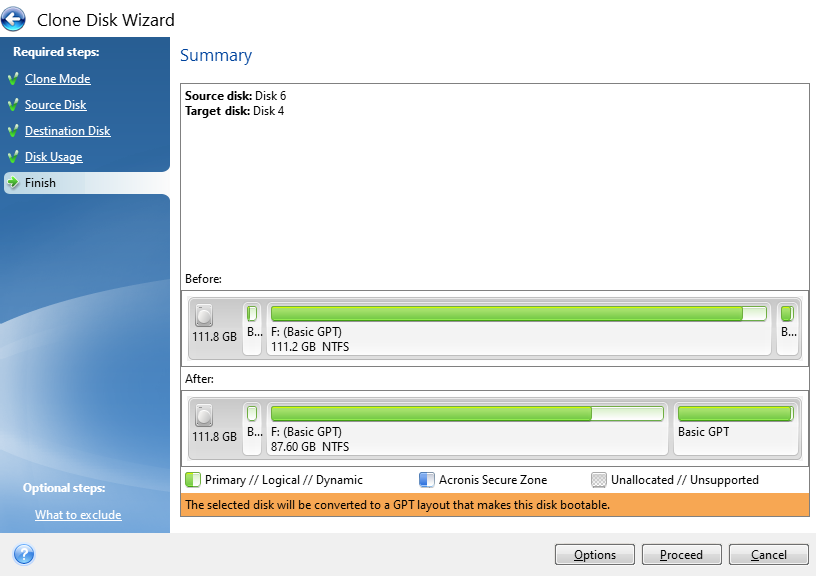
Confirm Settings and Start the Cloning Process
The final step is just confirming what your new disk will look like both at present and after the conversion process. In this example, this is an existing disk that is being flattened and re-purposed which is why the before info shows that the disk is full. If you are using a brand new disk, this will show up mainly empty as there will be nothing on it.
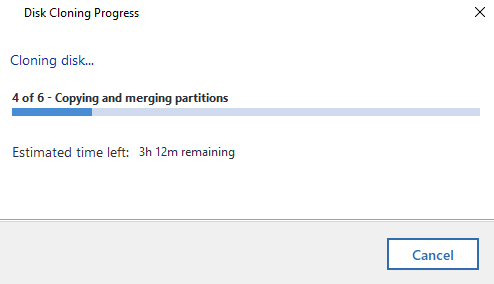
Now it’s just a case of sitting back and waiting. I’ve mentioned already Acronis is a slow piece of software for whatever reason. Just getting to this point probably took around 45 minutes believe it or not. The cloning process takes even longer. So make sure everything has plenty of juice to keep the power on throughout the process or you’ll end up losing a lot of time going through this process again.
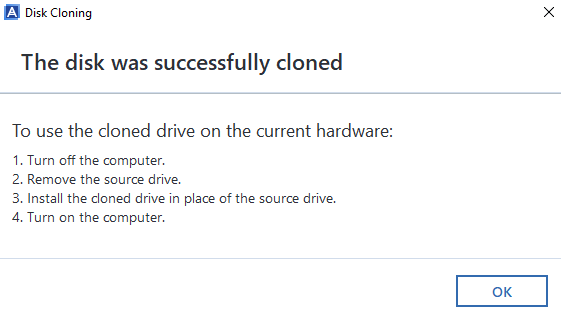
Disk Clone Successful
Woo! Finally, the cloning process has been complete. Now it’s just a case of plugging the new disk drive back into the computer you took the old one out of and everything should be back to normal, working fast again etc. If you do get any problems with this point, then generally the clone will have failed, even though Acronis says that it has worked. i.e. missing a bootable sector or some other form of corruption that is going to be near impossible to get to the bottom of.
Backups, Cloud, Redundancy Etc.
Ok, so we’ve run through the process of cloning hard disks either from HDD to HDD, HDD to SSD or SSD to SSD. Whatever your situation has been. What we haven’t covered off on this blog post yet is around backups, cloud and data redundancy etc. So let’s keep this topic really simple… your hard drives will fail at some point, so plan for it.
Use cloud service providers for storing your data, they have endless backups in place that are handled for you automatically without ever thinking about it. If you only have your data on your main hard disk in your computer, there is a chance that when your disk fails, you will permanently lose your data. Do not go backing up important data to external hard drives, this is manual, error prone and is still likely to result in some data loss for your data when one or more of your hard drives fail.
This is a topic that I could go into for a long time, but will avoid doing so within this blog post. Instead, let’s just keep things simple and ensure your data is backed up to the cloud. And make sure you can easily recover from a failed hard disk and be back up and running within hours, not weeks.
Notes on Failing Disks
Important to note that if you are working with a failing disk, then you can pretty much throw all of the above out of the window. Give it a go, but it’ll probably fail. You are probably best off getting a new disk drive and installing Windows 10 from scratch then you can copy the files over that you need (and backing them up to the cloud!). It’s a bit painful doing this but often it’s the only route when the disk drive has gone past the point of no return and is intermittently failing and doing random things. I’ve seen random things such as monitors flashing on/off with the Windows desktop going blank then back again on a repeat through to disk recovery software failing when it tries to read one single bit of data on the disk, usually about 95% into the process. It’s always best not to get to this point. Some other nuances I’ve seen is that BIOS wasn’t detecting the disk after an apparent successful clone, yet I could see the drive in Windows Device Manager when plugged into another machine, but it wasn’t showing up in Windows Disk Management. All very odd.
When thing get to this point, it’s time to just give up on the old disk, get Windows installed on a brand new one and salvage what you can. Learn your lesson and don’t make the same mistake twice. There are advanced recovery (and costly) options available to do deep dive recovery of data, which again on failing disks can even still be a bit hit and miss so you could be throwing good money after bad trying to recover this data, but it all depends on how important that data is to you.
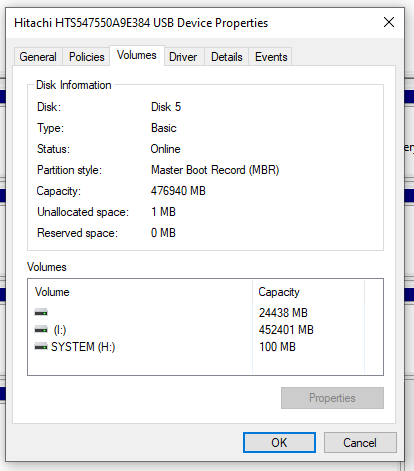
Check What Your Old Disk is Using – GPT or MBR
Something we didn’t go into in too much detail so far but is important to mention. GPT VS MBR – Make sure you check what the old disk is configured as. Or you’ll be repeating the processes again, or be forced to use a commercial bit of software to change GPT to MBR or the other way round. To do this, within Windows Disk Management, simply Right Click on the old drive and select Properties, then click on the Volumes tab where this info will be displayed. In this case we can see that the old drive is using MBR, so it’s best to configure the new disk drive also to use MBR because the computer this came from could (and likely will) have certain limitations at the BIOS layer about if MBR or GPT is supported (aka. UEIF Mode either Enabled or Disabled).
Note, Acronis is a pretty dumb and opinionated piece of software. It assumes that the Destination Disk Partition Mode (MBR VS GPT) is determined purely based on the computer that Acronis is running on. This is dumb, and quite frankly a fundamental flaw in the software in my opinion. In the vast majority of use cases in my experience, the Source Disk and Destination Disk are going to be plugged into an independent computer that is merely there to perform the copy and paste job.
MBR VS GPT is a Legacy VS Modern topic that is beyond the scope of this blog post. But what is important to note beyond the disk drive is that this comes down to the Motherboard’s BIOS Settings in relation to UEIF which is either Enabled or Disabled. Even still, there can be many compatibility issues in this space.
Sometimes, it’s just more effort than it is worth trying to upgrade a computer though. If it’s old, the Old HDD is old, then all the other components are old and slow. Sometimes it’s just more economic to throw away (recycle) the old and get a brand new computer and/or start with a fresh installation of Windows and go from there.
There are many bits of software that can help with cloning disks include: Clonezilla, Macrium Reflect Free, DriveImage XML, SuperDuper and many more. Many come with free basics and trial periods, but generally if you want to do something in full with an easy user experience, then you’re going to be using the commercial offerings.
After personally getting rather frustrated with Acronis, I decided to have a little rant on the Acronis Support Forums. Summary being “Unfortunately this is very unlikely to change for all users of Acronis True Image! This is because Acronis no longer support or develop this product.” And “The MVP community have been asking for this for some years but without any success.”. Not a very positive message, but at least an honest one from a senior member of the community given the lack of engagement from Acronis directly.
Summary
Hopefully this has been a helpful and detailed blog post for how to clone a hard disk drive (HDD) or solid state drive (SSD) and how you can handle this process for either failing disks or just upgrading disks to newer, faster and larger models.
Please take care when performing these actions and if you aren’t sure what you are doing, then leave this to the professionals. There are a lot of nuances with these types of actions which can be extremely destructive if you get this wrong. Be careful.
Amazon Linux (aka. Amazon Linux 1) was straight forward to get Let’s Encrypt setup, it was a breeze and the documentation wasn’t too bad. I don’t know why Let’s Encrypt support for Amazon Linux 2 just isn’t where it needs to be, given the size and scale of Amazon Linux 2 and the fact that Amazon Linux is now an unsupported operating system. It’s likely because Amazon would prefer you to use their AWS Certificate Manager instead, but what if you just want a Let’s Encrypt certificate setting up with ease. Let’s take a look at how you get Let’s Encrypt setup on an AWS EC2 instance that is running Amazon Linux 2 as the operating system/AMI.
Assumptions
We’re assuming you’ve got Apache / Apache2 installed and set up already with at least one domain name. If you are using Nginx or other as your Web Server software then you’ll need to tweak the commands slightly.
How to Install Let’s Encrypt on Amazon Linux 2
Firstly, we need to get the Let’s Encrypt software installed on your Amazon Linux 2 machine, this is called Certbot. For those of you looking for the quick answer, here’s how you install Let’s Encrypt on Amazon Linux 2 along with the dependences;
For those of you looking for a bit more information. There are a few fairly undocumented dependencies to get this working. So to get started you’ll want to install the dependencies for Let’s Encrypt on Amazon Linux 2 including;
Epel, aka. The Extra Packages for Enterprise Linux, from the Amazon Linux Extras repository
Python2 Certbot Apache using Yum
Certbot Apache using Yum
Mod_SSL, Python Certbot Apache using Yum
As it was a bit of a pain to get this configured, I’m fairly sure one of the above isn’t required, I just can’t recall which one that was.
How to Configure Let’s Encrypt on Amazon Linux 2 for a Domain
So now you’ve got Let’s Encrypt installed on Amazon Linux 2, it’s time to generate an SSL certificate for your domain that is hosted. For the purpose of simplicity we’re going to assume you’re running very basic setup such as www.example.com/HelloWorld.html. There are other nuances you need to consider when you have a more complex setup that are outside of the scope of this blog post.
What you’ll notice in the above is that we’re using Certbot and telling it that we’ve got an Apache Web Server behind the scenes and that we want to generate an SSL certificate for the Domain (-d flag) yum-info.contradodigital.com.
Simply run that command and everything should magically work for you. Just follow the steps throughout.
Summary
The above steps should help you get setup using Let’s Encrypt on Amazon Linux 2 without much fuss. Amazon Linux 2 really does feel like it has taken a step back in places, Amazon Linux 1 had more up to date software in places, and easier to work with things like Let’s Encrypt. But hey. We can only work with the tools we’ve got on the AWS platform. Please leave any comments for how you’ve got along with installing Let’s Encrypt and getting it all set up on Amazon Linux 2, the good, the bad and the ugly.
AWS. With great power comes with great responsibility. AWS doesn’t make any assumptions about how you want to backup your resources for disaster recovery purposes. To the extent that they even make it easy for you to accidentally delete everything when you have zero backups in place if you haven’t configured your resources with termination protection. So, let’s think about backups and disaster recovery from the start and plan what is an acceptable level of risk for your own setup.
Risk Appetite Organisationally and Application-ally
OK, that’s a made up word, but you get the gist. You need to assess your appetite to risk when it comes to risk, and only you can do this. You have to ask yourself questions and play out roll plays from “What would happen if a single bit of important data got corrupted and couldn’t be recovered on the Live system?” all the way through to “What would happen if the infrastructure running the Live system got hit by a meteorite?”. Then add a twist into these scenarios, “What would happen if I noticed this issue within 10 minutes?” through to “What would happen if I only noticed this issue after 4 days?”.
All of these types of questions help you to assess what your risk appetite is and ultimately what this means for backing up your AWS infrastructure resources such as EC2 and RDS. We are talking specifically about backups and disaster recovery here, not highly available infrastructures to protect against failure. The two are important aspects, but not the same.
As you start to craft your backup strategy across the applications in your corporate environment and tailor the backup plans against different categories of applications and systems into categories such as Business Critical, Medium Risk, Low Risk etc. then you can determine what this looks like in numbers. Defaults for frequency of backups, backup retention policies and such like.
How to Backup EC2 and RDS Instances on AWS Using AWS Backup
To start with the more common services on AWS let’s take a look at how we back these up and what types of configurations we have available to align out backup strategy with the risk appetite for the organisation and the application itself. The specific service we’re interested in for backing up EC2 and RDS instances on AWS is creatively called….. AWS Backup.
AWS Backup allows you to create Backup Plans which enable you to configure the backup schedule, the backup retention rules and the lifecycle rules for your backups. In addition, AWS Backup also has a restore feature allowing you to create a new AWS resource from a backup so that you can get the data back that you need and/or re-point things to the newly restored instance. Pretty cool really.
The first thing you want to do to get started is to create a Backup Plan. Within the creation process of your Backup Plan, you can configure all the items mentioned previously. Usually we’d walk through the step by step to do this, but really you just need to walk through the settings and select the options that suit your specific needs and risk appetite.
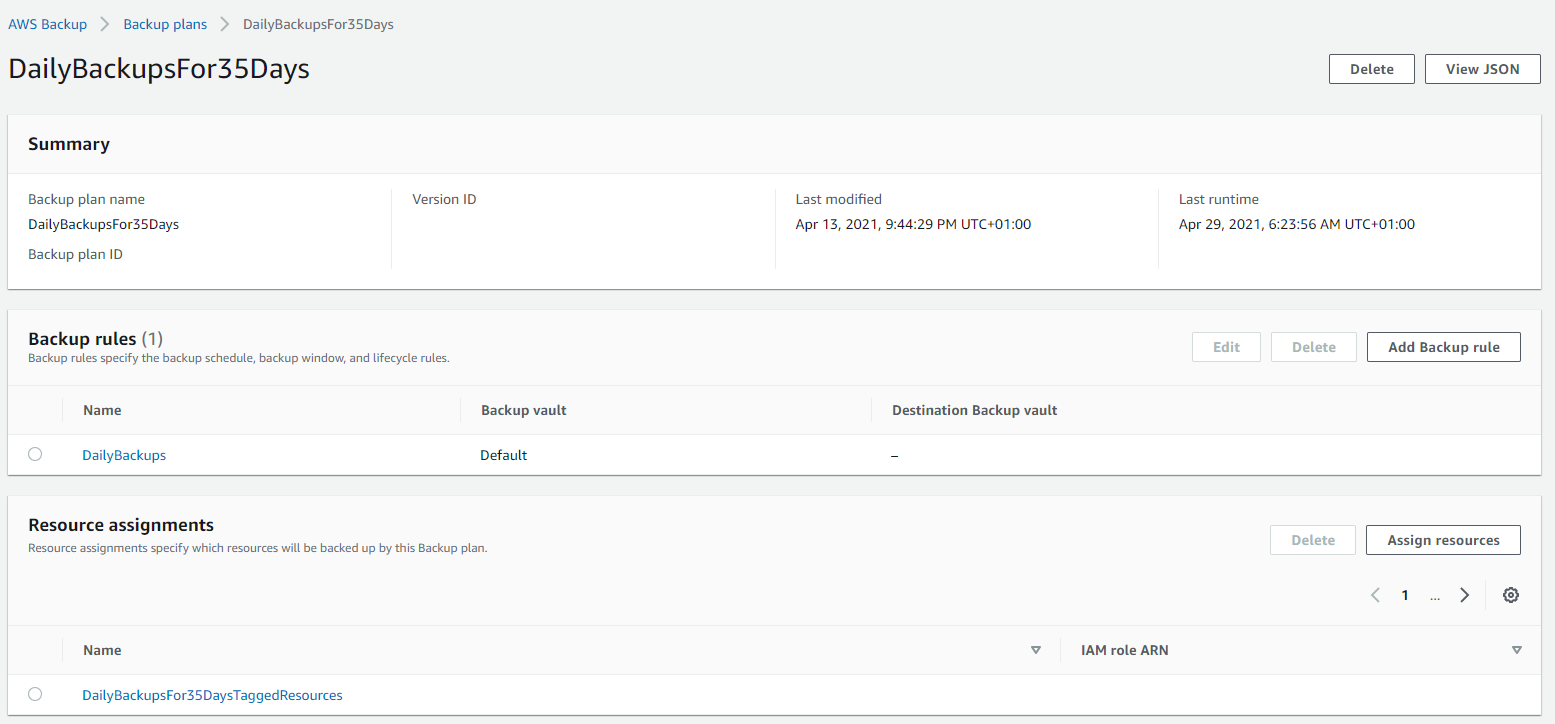
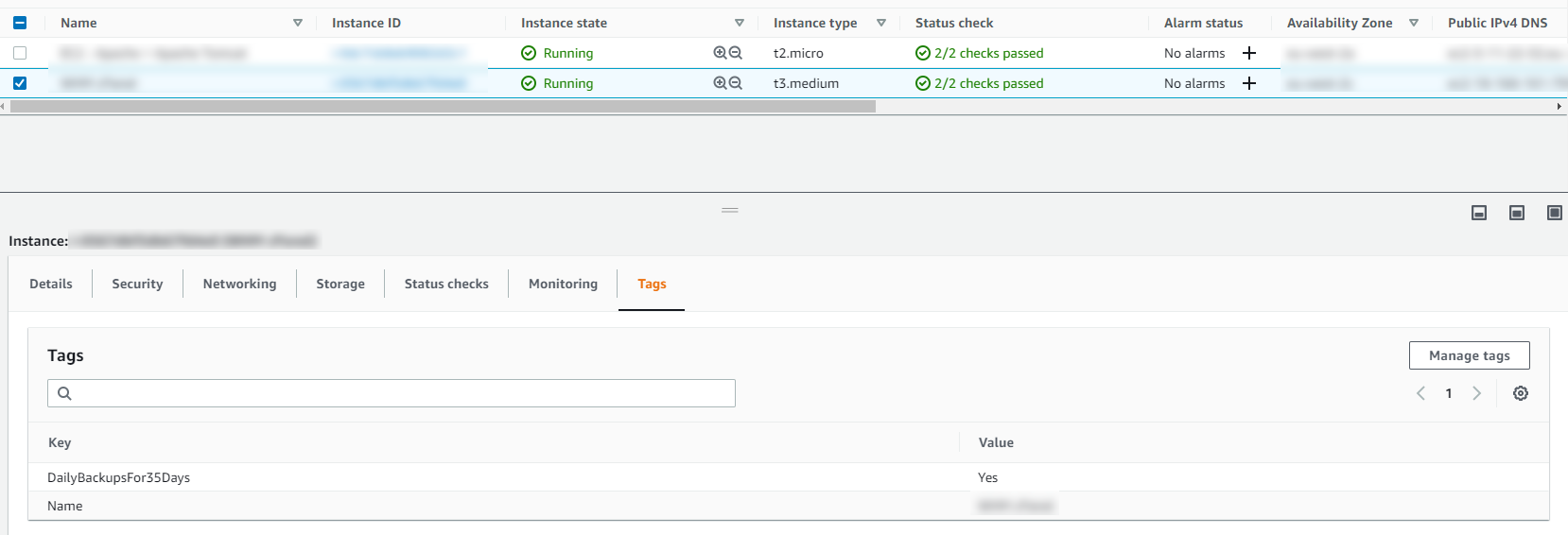
Below is a basic Backup Plan that is designed to run daily backups with a retention policy of 35 days, meaning we have 35 restoration points. You’ll also notice that instead of doing this for specific named resources, this is backing up all resources that have been tagged with a specific name.
Tagged Resources;
The tagged resource strategy using AWS Backup is an extremely handy way of managing backups as you can easily add and remove resources to a Backup Plan without ever touching the Backup Plan itself. Naturally you need a proper process in place to ensure things are being done in a standardised way so that you aren’t constantly hunting around trying to figure out what has been configured within AWS.
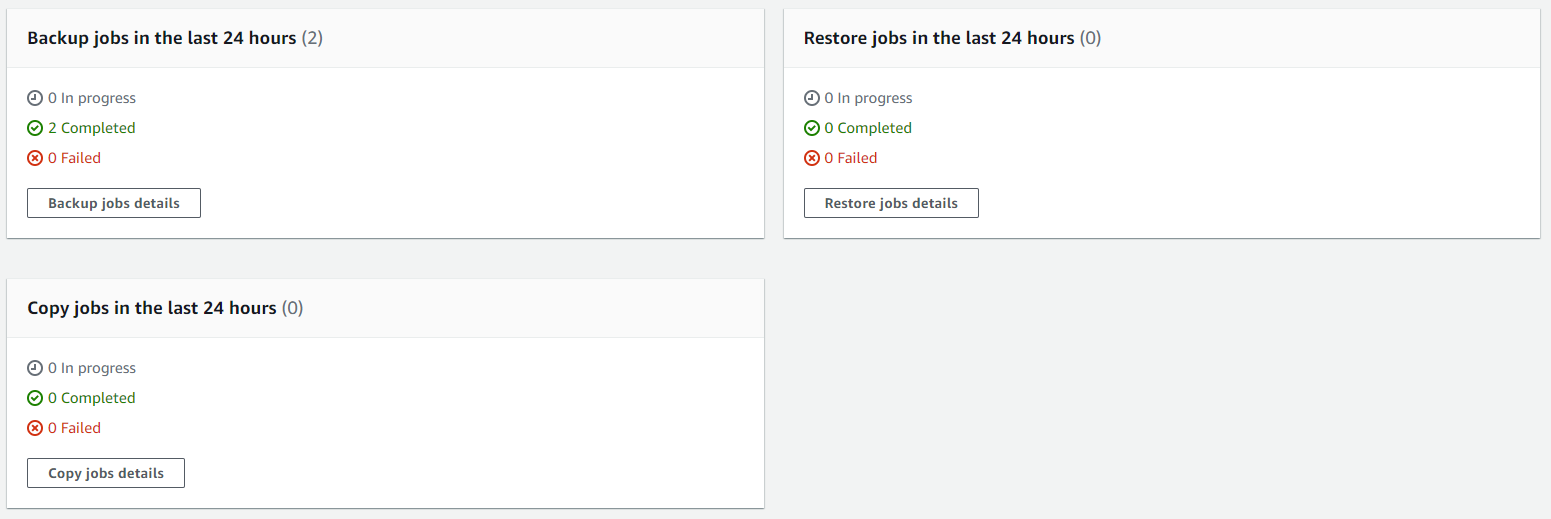
Running Backups
Once you have your Backup Plans in place, you can then start to see easily the backups that have been running, and most importantly if they have been successful or if they have failed.
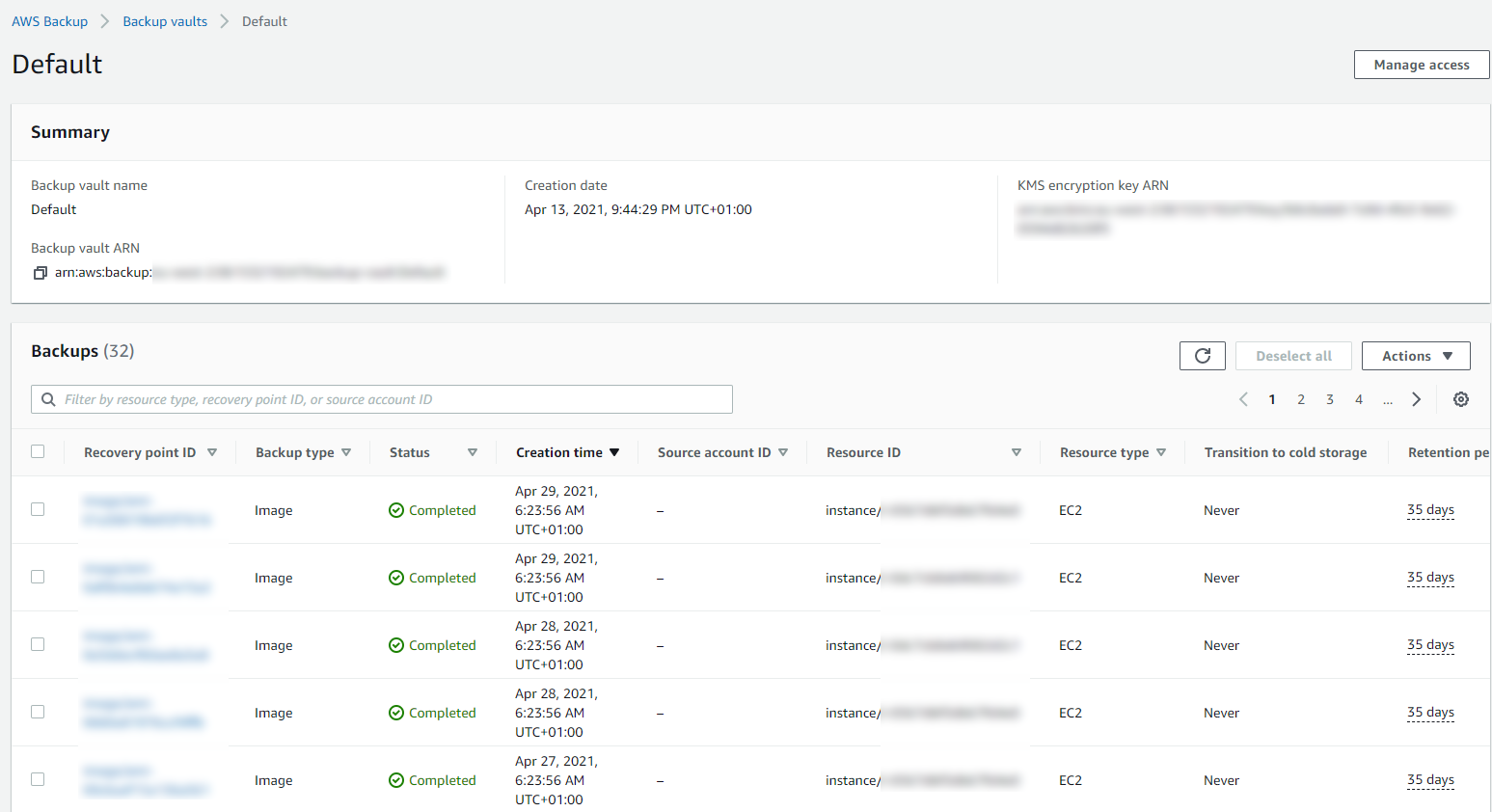
Then you can drill into the details and see all of your restoration points within your Backup Vault and ultimately this is where you would restore your backups from if you ever need to do that;
Summary
Hopefully that’s a whistle stop tour of how to backup your AWS infrastructure resources such as EC2 and RDS on AWS using AWS Backup. The best advice I can give when you are implementing this in the real world is that you need to truly understand your IT landscape and create a backup strategy that is going to work for your business. Once you have this understood, clicking the right buttons within AWS Backup becomes a breeze.
Don’t do it the other way round, just creating random backups that don’t align with the business goals and risk appetites. You will end up in a world of pain. No-one wants to go reporting to the CEO….. IT: “Oh we only have backups for 7 days.” ….. CEO: “What?!?!?! We are legally required to keep records for 6 years! WTF!”. You get the gist.
This can be quite an enormous topic to cover, so here’s some further reading if you want to know more;
So this isn’t quite as straight forward as it probably should be and the documentation from AWS is the usual, not great. So let’s cut through the nonsense and take a look at what you need to do so that you can quickly and easily get your DNS Zone Files and DNS Records migrated.
Assess Your Current DNS Provider, Zone Files, Domains and Nameserver Configurations
The first things you want to do before you start any kind of migration of your DNS over to AWS Route53 is the plan. Plan, plan and plan some more. Some of the nuances I came across with a recent DNS migration piece of work from DNS Provider X to AWS Route53 included some niggles such as vanity nameservers. The old DNS provider had things configured to ns1.example.com and ns2.example.com, then domain1.com and domain2.com pointed their nameservers to ns1.example.com and ns2.example.com which was quite a nice touch. This doesn’t quite work on AWS Route53 and I’ll explain that in a bit more detail in a moment. Another niggle that we came across that you need to plan properly and that is to make sure you have absolutely everything documented, and documented correctly. This needs to include for every domain at an absolute minimum things such as;
Domain name
Sub-Domains
Registrar (inc. login details, and any Two Factor Authentication 2FA steps required)
Accurate Zone File
The vast majority of people just have a Live version of their DNS Zone Files, which in itself is risky because if you had an issue with the DNS Provider X and you had no backup of the files, you could be in for a whole world of pain trying to re-build things manually in the event of a critical failure.
How AWS Route53 Manages Hosted Zones
So back to the point I mentioned earlier around vanity nameservers and why this doesn’t quite work in the way the old DNS Provider X worked. When you create a new Hosted Zone within AWS Route53, Amazon automatically assigns 4x random nameservers of which you can see an example below;
ns-63.awsdns-07.com
ns-1037.awsdns-01.org
ns-1779.awsdns-30.co.uk
ns-726.awsdns-26.net
What you will instantly notice here is that there are a lot of numbers in those URLs which should give you an idea of the complexity of the nameserver infrastructure behind the scenes on the Route53 service. What this also means is that because these nameservers are automatically generated you can’t configure two Hosted Zones to use the exact same nameservers to get the similar vanity nameserver setup explained earlier.
The reality is, this approach while is fairly common for complex setups, the majority of standard setups this isn’t an issue for. If you want to get vanity nameservers set up on AWS for a single domain, i.e. ns1.domain1.com and ns1.domain2.com etc. then you can do this if you wish.
Export Zone Files from your Old DNS Provider
The first step of this process is to export your Zone Files from your old DNS provider. What you will find from this process is that ever provider will export these slightly differently, and this highly likely won’t be in the format that Route53 needs when you import the Zone Files.
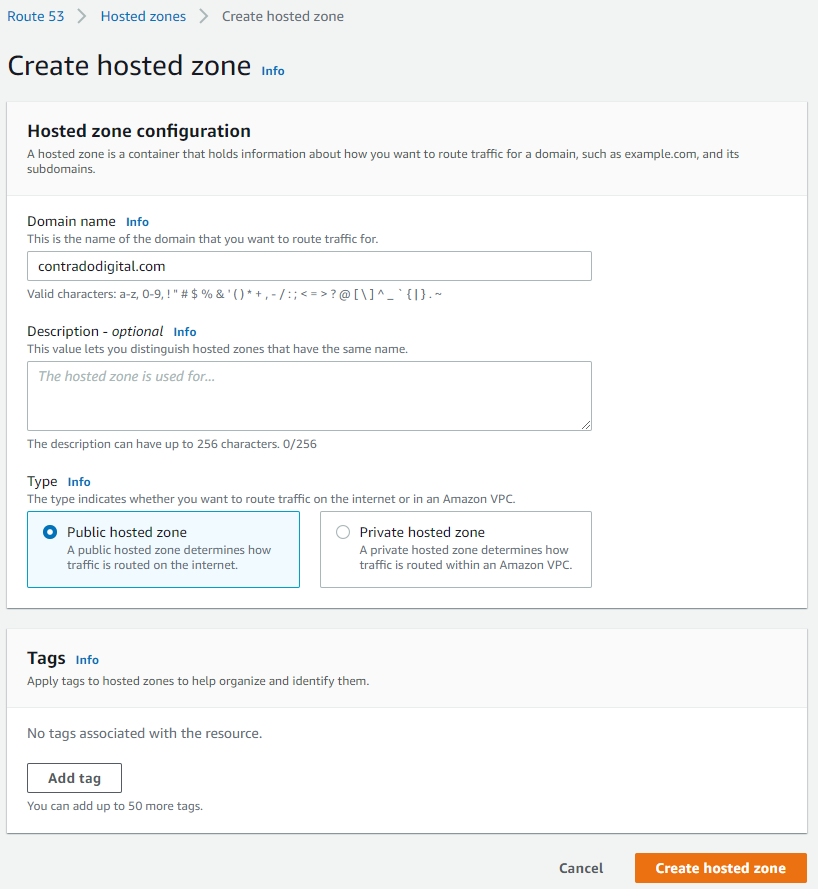
Create a Hosted Zone in Route53
This step is straight forward, just click the button.
Importing Zone Files to your Hosted Zone
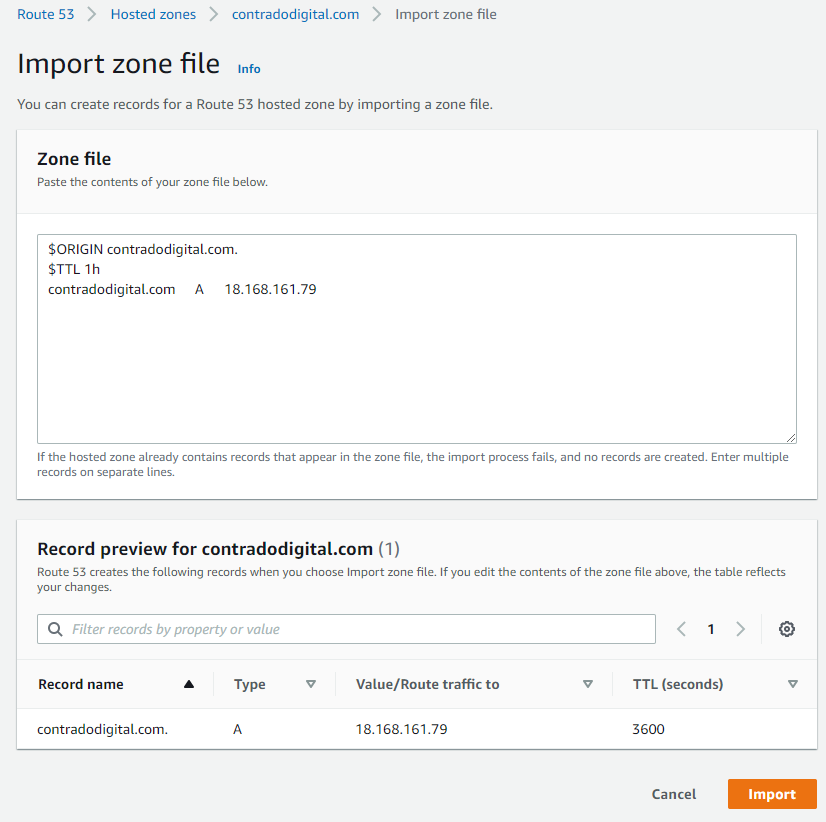
As such, it’s time to prepare your Zone Files to be able to be imported into Route53 successfully. The format you need for your zone file import is as follows;
$ORIGIN contradodigital.com.
$TTL 1h
contradodigital.com A 18.168.161.79
Notice the couple of additional lines you need to add in which likely won’t be included from your export from your old provider. The above is just a very basic set of DNS entries. The reality is you will likely have 10 – 50+ DNS entries per domain depending on the complexity of your setup. One to keep an eye out on is that you may find certain record types don’t quite import seamlessly. Just a few niggles that I came across doing this included;
MX records required a 10 included, i.e. contradodigital.com MX 10 contradodigital-com.mail.protection.outlook.com
DKIM (TXT) and SPF (TXT) records had to be re-generated and imported manually as the format just didn’t quite work for the automatic import for some reason.
And I’m sure you’ll come across a few issues along the way that I haven’t mentioned here.
Summary
Hopefully this guide on how to import Zone Files into AWS Route53 helps to clarify some of the niggles around using the Zone File Import feature. To reiterate around this process when you are doing this in a real situation, make sure you plan this properly, have clear checklists and processes that you can methodically work through to ensure things are working as you do them. These types of changes can have a significant disruption to live systems if you don’t implement these things correctly.
We’ve got a lot of complex topics to cover here, so for the sake of simplicity we’re only going to touch on the really high level basics of these concepts to help you understand how all these different pieces of the puzzle are connected together. When you’re first getting started in the world of IT, it’s often a bit of a puzzle how all these things are plugged together under the hood which can cause a lot of confusion. By knowing how things are plugged together, i.e. how the internet works, you will have a significantly better chance of working with existing setups, debugging problems fast, and most importantly building new solutions to bring your creative ideas to life.
Firstly, let’s get some basic terminology understood;
Registrar = This is where you purchased your domain name from, i.e. example.com
Nameservers = This is the where the authority starts for your domain, i.e. it’s the equivalent of “tell me who I need to talk to who can point me in the right direction to get to where I want to go”. It’s the authority on the subject whose opinion on the matter is #1.
DNS = This is the gate keeper to determine how traffic into your domain flows to where it needs to go. Think of your DNS like Heimdall from the Thor movies. You configure your nameservers to act in a way that you want, i.e. requests from www.example.com, should ultimately route to server IP address, 1.2.3.4, so that you don’t need to go remembering a bunch of IP addresses like a robot – or in the Heimdall world, “Heimdall…” as Thor screams in the movies, and he is magically transported from Earth to his home world of Asgard. Likewise, if Loki wants to visit a different planet, he just asks Heimdall to send him there and the magic happens. DNS can appear like magic at times, but it’s actually really simple once you understand it. DNS is a hard concept to explain simply, we’ll do another blog post on this topic in more detail another time. Hopefully this basic comparison helps you to at least grasp the topic at a high level.
Servers = This is where things get fairly messy. This could be a physical piece of hardware that you can touch and feel, or could be a virtualised system, or visualised system within a virtualised system. There are multiple layers of virtualisation when you get down to this level. Although it’s not that important for the purpose of this blog post. Ultimately, all we care about is that the traffic from www.example.com, or something-else.example.com, gets to where it needs to when someone requests this in their web browser.
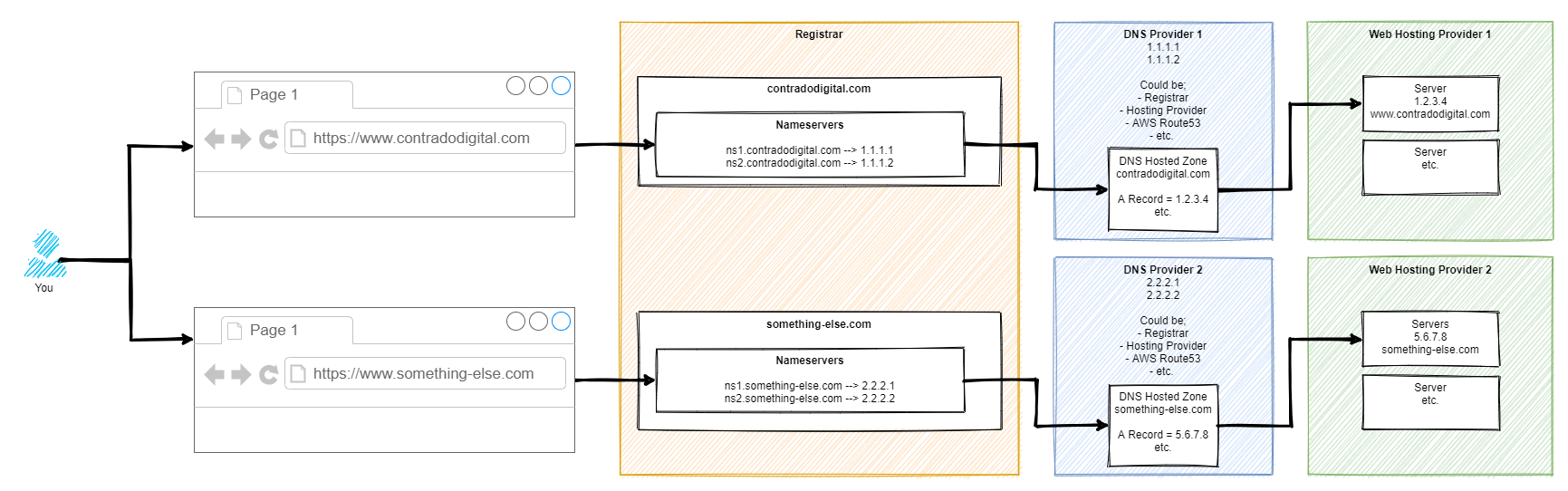
As mentioned, this is a difficult concept to explain simply in a blog post as there are so many different considerations that need to be made. But hey, let’s give it a go, with a basic diagram. There are elements of this diagram that have been simplified to help you understand how the different bits fit together.
So here’s how it works step by step. For those of you who are more technical than this blog post is aimed at, yes there are a few steps in between things that have been cut out for simplicity.
Step 1 – Type Website Address into Web Browser
This step is fairly basic so we’ll skip over this one.
Step 2 – Web Browser Asks for Authoritative Nameserver for Website
This part is very complex in the background, so we’re not going to delve into these details. For the purpose of simplicity, ultimately your web browser says “Give me the name servers for contradodigital.com”, and ‘the internet’ responds with, “Hey, sure, this is what you’re looking for – ns1.contradodigital.com and ns2.contradodigital.com”.
As with all hostnames, they ultimately have an IP address behind them, so this is what then forwards the request onto the next step.
Step 3 – DNS Provider with Hosted Zones
A Hosted Zone is simple something such as contradodigital.com, or something-else.com. Within a Hosted Zone, you have different types of DNS Records such as A, AAAA, CNAME, MX, TXT, etc. (that last one isn’t an actual record, just to confirm 🙂 ). Each of these record types do different things and are required for different reasons. We’re not going to be covering this today, so for simplicity, the A Record is designed to forward the request to an IP Address.
So your DNS Provider translates your request for www.contradodigital.com into an IP address where you are then forwarded.
Step 4 – Web Hosting Provider Serves Content
Finally, once your web browser has got to where it needs to get to, it starts to download all the content you’ve asked for from the server on your web hosting provider to your web browser so you can visualise things.
This part of the diagram is so overly simplified, but it is fine for what we are discussing. The reality of this section is that this could quite easily be 10-20 layers deep of ‘things’ when you start to get into the low level detail. But that’s for another time.
Hopefully this blog post has given you a good understanding of how your Registrar, Nameservers, DNS and Servers are connected together under the hood. When you truly understand this simple approach, play around with a system that isn’t going to break any live environment, so you can start to test different types of configurations along the way to see how they behave. If you don’t know what you are doing, do not play around with these things on a Live system as you can do some real damage if you get things wrong which can result in your services being offline for a significant period of time.