by Michael Cropper | Aug 9, 2022 | Developer |
This is quite a complex topic, and one that all depends on your specific setup. So we’re going to take a look at some of the options for how to get this set up with ease. Is what we’re going to talk through the best practice? Not sure. But I’ve not found any useful information online for a better approach, so to quote Admiral Adama from Battlestar Galactica when asked the question “So what’s your plan here?” he answers “Personally, I tend to go with what you know. ‘Til something better turns up”. So if the readers of this blog post have any better ways of doing this, please do share in the comments.
Physical Network Hardware
So let’s get some basics documented. The reality is that every single physical network hardware is going to be different for every organisation. But fundamentally and at the most basic level everyone has at a minimum: Modem –> Firewall –> Managed Switch –> XCP-NG Server –> Virtual Machine(s)
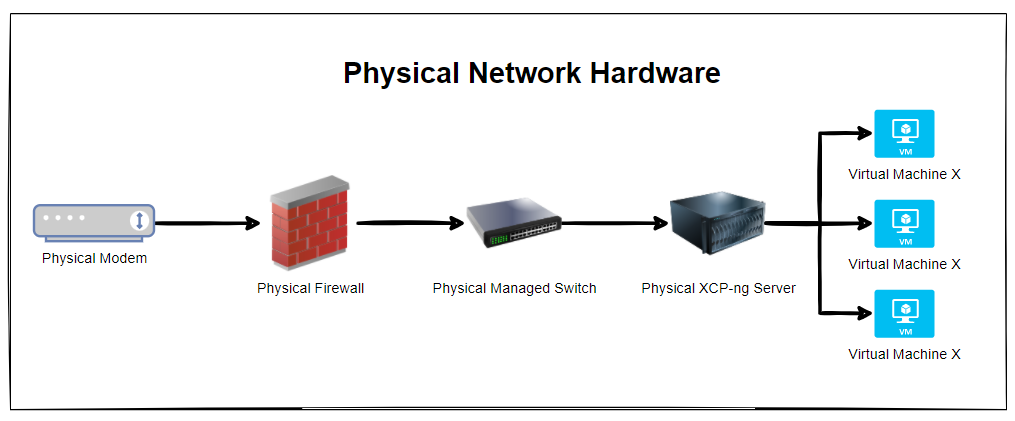
The reality is that in most home setups when people are getting started, most people start off with a single device supplied by the ISP (Internet Service Provider). Often these devices act as everything and nothing, so they perform the absolute basic requirements of a modem, a firewall and a switch, but fail on most things as they can’t handle VLANS, they can’t handle complex firewall rules and they can’t effectively manage complex networks. Typical jack of all trades, master of none.
Ultimately if you are in this home lab setup and wondering why things don’t work. It’s highly likely because you simply don’t have the physical hardware that you need to achieve what you want. Consumer grade hardware simply doesn’t cut it, even the high end consumer grade hardware as this is often designed to visually look powerful through curves/edges and more antennas in design rather than actually being powerful under the hood. Unfortunately in the UK we don’t particularly have the equivalent of an ecommerce store for this kind of stuff to make life easy, the way things work is often behind complex business to business commercial relationships and ‘special’ pricing etc. It’s an absolute nightmare. Perhaps I need to get around to building a business model to help to simplify the supply chain for these things, when I get the time. But hey, I digress. Back to the topic at hand.
Now things get a little more complex than the above as there are physical cables that are connecting the different physical devices, so let’s expand the above architectural diagram to understand the next level of detail. Here we have the setup whereby the firewall has 3x physical ports on the device and we have configured the firewall to have a simple setup of one port = one VLAN.
In reality, many VLANs often share a single physical port on the physical device, but let’s leave that for another blog post to cover off. So then we have the managed switch with the basic setup of 3x inbound connections and 3x outbound connections, each matching a one to one relationship to keep things simple. Again, the reality of any real world implementation is that we use things called Trunk Ports which is just a term that means a physical port that allows traffic to flow to the next physical device for every VLAN and untagged (aka. non-VLAN traffic).
What this ultimately leaves us with is the setup as follows;
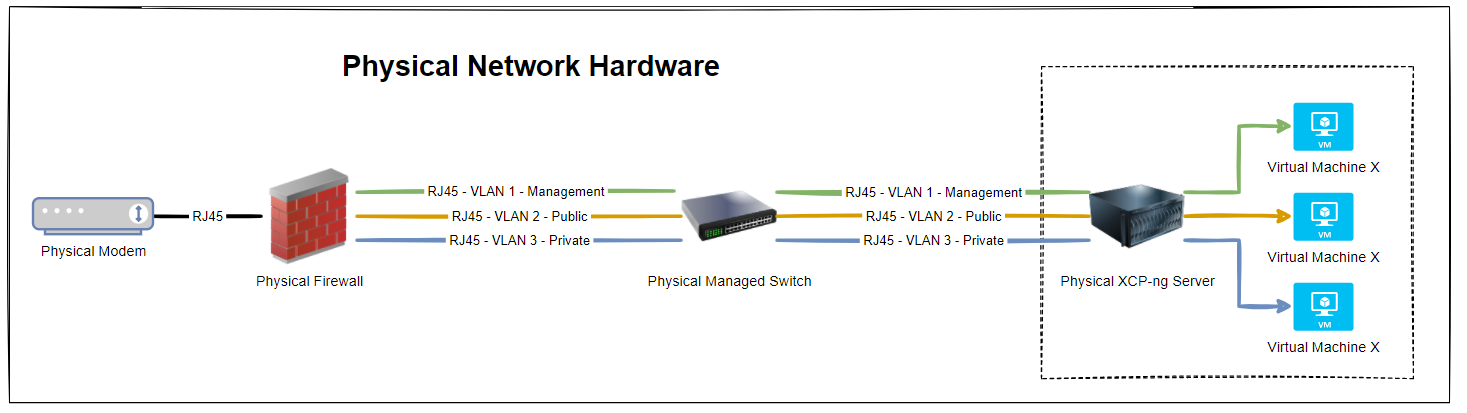
So we have 3x physical RJ45 cables connected between the physical firewall and the physical managed switch, and then another 3x physical RJ45 cables connected between the physical managed switch and the physical type-1 bare metal hypervisor XCP-ng Server. Everyone’s setup is going to be different, but if you’re working with Ubiquiti/UniFi then this guide on how to setup a UniFi managed switch is going to be handy.
But, we’ve jumped ahead a little. You’ll notice in the above diagram that the virtual machines are magically attached to the correct VLANS. But how? You may ask.
How to Configure XCP-ng Centre Networks on First Setup
When you first get XCP-ng Server setup and XCP-ng Centre setup, you’ll notice that when you plug in all the Ethernet cables that you are simply presented with a bunch of un-identified networks that you need to figure out what to do with;
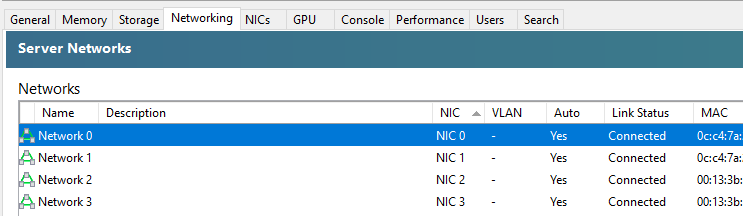
The networks that are listed here within XCP-ng Centre are directly related to the physical ports that you have available on your XCP-ng Server. So you’re probably thinking, awesome, let’s get started and get a virtual machine spun up and get cracking. But it’s not so straight forward. How do you know which network to attach the virtual machine to? After all, your choice here can have security implications depending on your use case. You don’t want a publicly accessible virtual machine to have access to your management network.
So we need to get into the topic of how to identify what networks in XCP-ng Centre map to what VLANs so that you can label them correctly and ultimately use them properly within your configuration. As with everything important, naming conventions and terminology is extremely important so make sure you agree this within your own organisations as appropriately.
The best way I’ve found to easily get this mapped in the first instance is actually quite simple, while not obvious, and it also feels quite rudimentary, it does work. Simply create multiple virtual machines, each one dedicated to a single network, then see what IP address it gets assigned from your DHCP server (likely managed on your firewall and enforced through VLAN configuration in the firewall and managed switch).
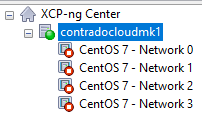
This is assuming you’ve already got your XCP-ng Centre configured to connect to your ISO Storage Repository for loading operating systems.
This step certainly feels a bit like using a sledgehammer to crack a nut, but it works. But I’ve yet to find a simpler way to achieve this. Once you’ve gone through this process and run the equivalent of “what’s my IP” (aka. ipconfig or ifconfig etc.) on the virtual machines once you’ve set them up and SSH’d into them, you’ll know definitively which network they are configured against.
So now you need to rename your networks within XCP-ng Centre.
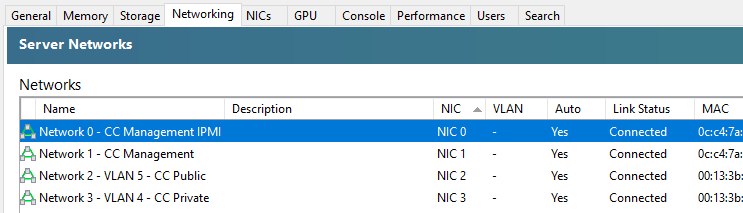
You’ll notice in the above screenshot that we don’t have the VLAN column populated, and that is purely because there are pending internal decisions to be made around the above setup on this specific use case, but you get the idea of how you can make sure the Network Interface Cards (NICs) map through to the XCP-ng Centre networks.
As with everything in IT “It depends” 😀
Summary
The reality is that what we have gone through in this blog post is an extremely basic setup in the real world. What I hope has been conveyed throughout this blog post is one practical way of mapping when things are physically plugged-in to different network ports and how we can determine which actual networks they belong to before we start deploying different virtual machines for different use cases.
by Michael Cropper | Aug 7, 2022 | Developer |
Ok, so we’ve done a recent blog post on how to setup XCP-NG Tools on CentOS 7. So this blog post is going to be a rather similar blog post which a few nuances.
Pre-Check
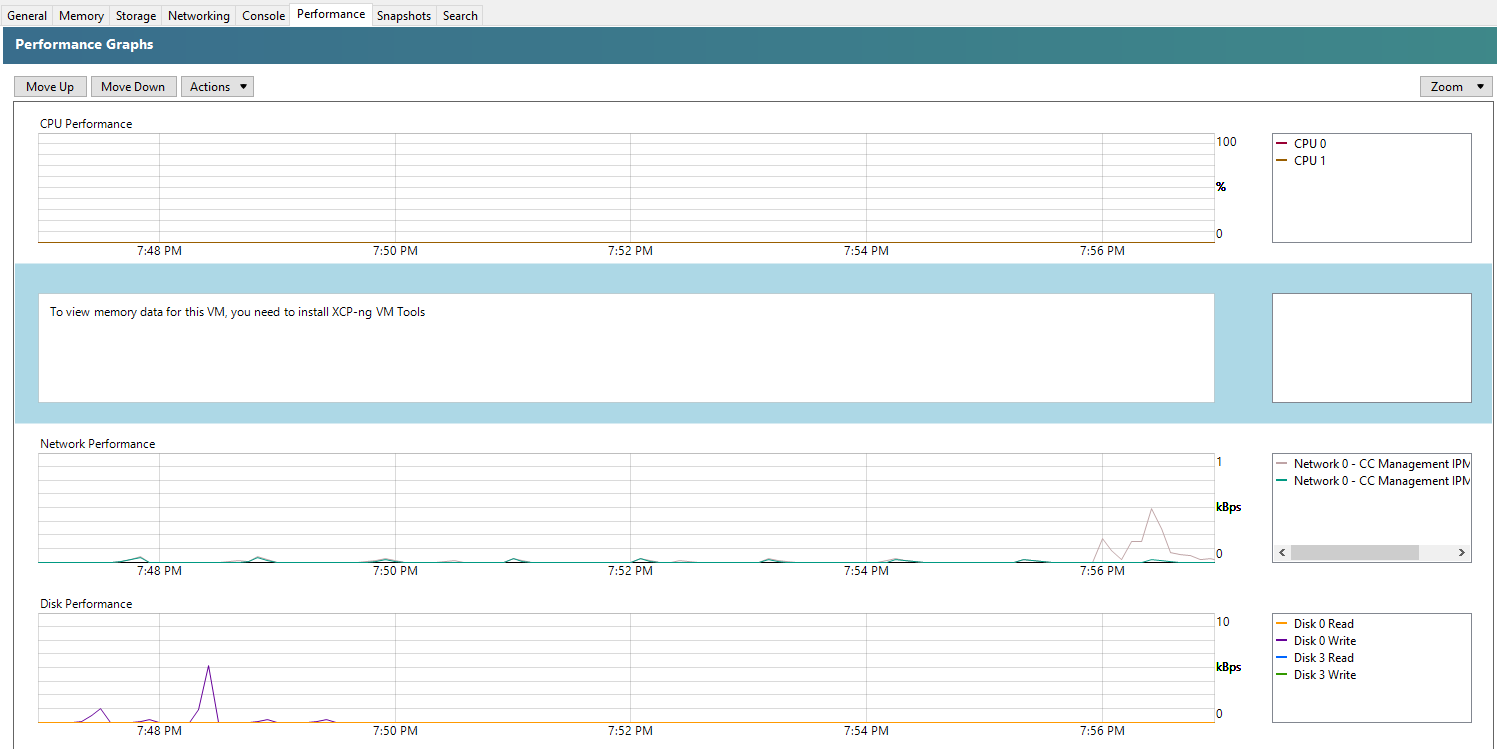
You’ll notice that XCP-NG Tools is not installed when you check the Performance tab against your Debian 11 Bullseye virtual machine as you’ll see the message “To view memory data for this VM, you need to install XCP-ng VM Tools”;
Step 1 – Insert the guest-tools.iso in the Virtual Disk
To do this, go into your virtual machine within XCP-NG Centre, then into the Storage tab, then make sure that within your DVD Drive you have the XCP-NG VM Tools is selected;

Step 2 – SSH Into the Virtual Machine
Next step is pretty straight forward, SSH into your virtual machine so you can run the commands to install XCP-NG Tools on Debian 11 Bullseye.
Step 3 – Switch to Sudo
This step is one that isn’t particularly well documented online. As of Debian 10 Buster release and also continued within Debian 11 Bullseye release, to switch to the sudo user you need to run the command;
sudo –

Step 4 – Mount the CD-ROM/DVD Drive
This step is to ensure that your Debian 11 Bullseye can access the contents of the virtual CD-ROM/DVD Drive that we configured within step 1. To do this, simply run the command;
mount /dev/cdrom /mnt/
What the above command is saying is…..Mount the folder path at /dev/cdrom to the folder location /mnt/ – There is nothing more to it than that.
Step 5 – Run the install script for XCP-NG Tools
Now that your Debian 11 Bullseye virtual machine has access to the contents in your virtual CD-ROM/DVD Drive which contains the guest-tools.iso contents, it’s time to run the installation script.
bash /mnt/Linux/install.sh
Follow the steps and you’re on your way. You’ll know that XCP-NG Tools has been successfully installed because you’ll get a confirmation message;
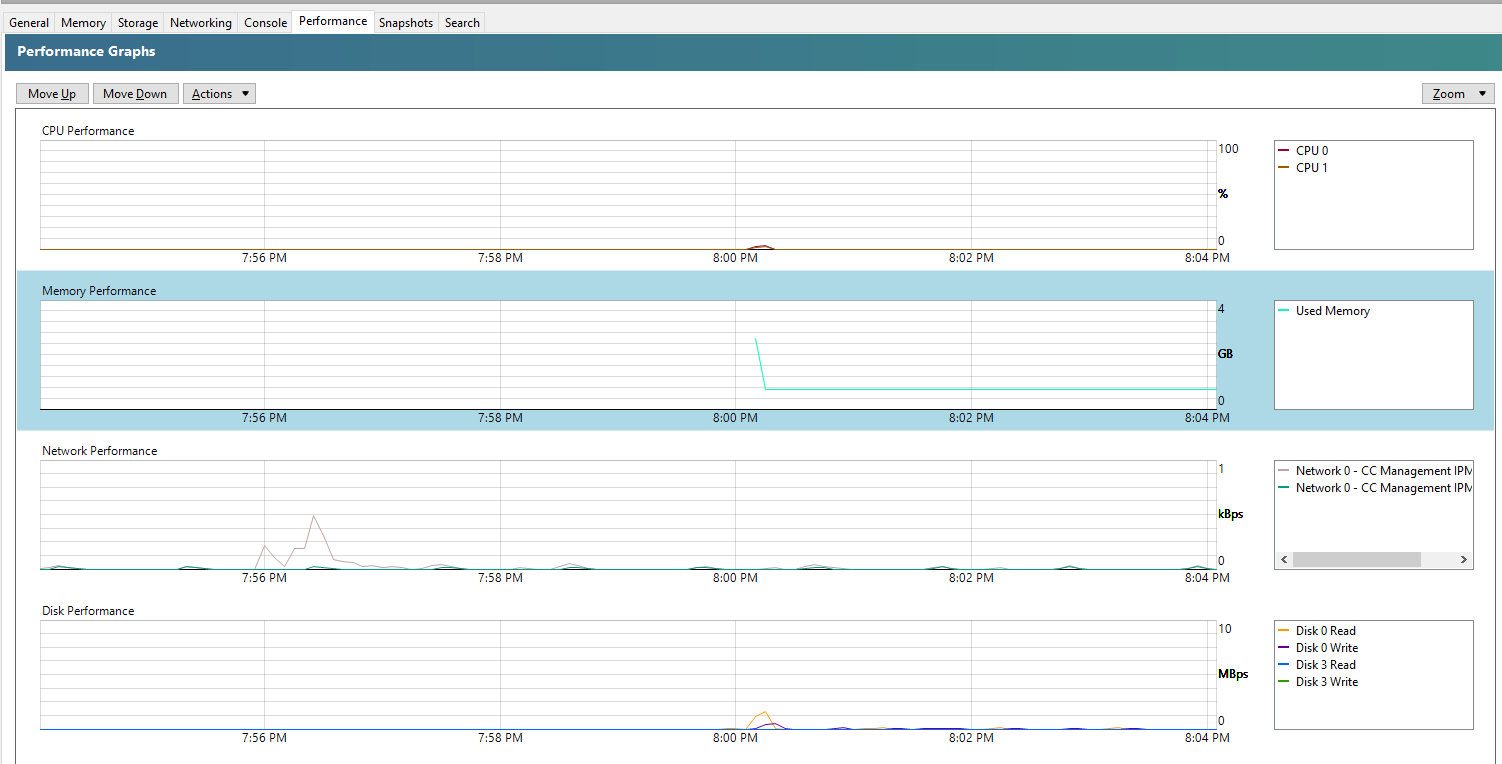
And you’ll also note that within the Performance tab against your Debian 11 Bullseye virtual machine that the memory data starts to come through in a matter of minutes at the absolute most, in most cases in about 30 seconds, even without rebooting;
Summary
When you follow these simple steps, it’s a few clicks and commands to get XCP-NG Tools up and running on Debian 11 Bullseye via XCP-NG Centre. For every virtual machine that you setup, make sure you install XCP-NG Tools to make your life as easy as possible.
by Michael Cropper | Aug 7, 2022 | Developer |
Short blog post with a simple few commands to get you up and running quickly. XCP-NG Tools is also commonly referred to as Xen Tools, even though the two are technically different, XCP-NG Tools is based on Xen Tools, but that’s a topic for another day.
Pre-Check
You’ll notice that XCP-NG Tools is not installed when you check the Performance tab against your CentOS 7 virtual machine as you’ll see the message “To view memory data for this VM, you need to install XCP-ng VM Tools”;
Step 1 – Insert the guest-tools.iso in the Virtual Disk
To do this, go into your virtual machine within XCP-NG Centre, then into the Storage tab, then make sure that within your DVD Drive you have the XCP-NG VM Tools is selected;
Step 2 – SSH Into the Virtual Machine
Next step is pretty straight forward, SSH into your virtual machine so you can run the commands to install XCP-NG Tools on CentOS 7.
Step 3 – Mount the CD-ROM/DVD Drive
This step is to ensure that your Linux CentOS 7 can access the contents of the virtual CD-ROM/DVD Drive that we configured within step 1. To do this, simply run the command;
mount /dev/cdrom /mnt/
What the above command is saying is…..Mount the folder path at /dev/cdrom to the folder location /mnt/ – There is nothing more to it than that.
Step 4 – Run the install script for XCP-NG Tools
Now that your CentOS 7 virtual machine has access to the contents in your virtual CD-ROM/DVD Drive which contains the guest-tools.iso contents, it’s time to run the installation script.
bash /mnt/Linux/install.sh
Follow the steps and you’re on your way. You’ll know that XCP-NG Tools has been successfully installed because you’ll get a confirmation message;
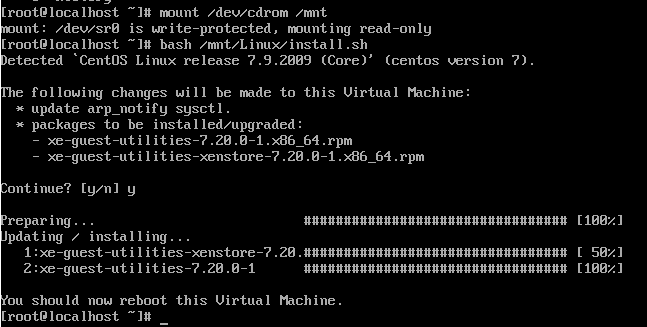
And you’ll also note that within the Performance tab against your CentOS 7 virtual machine that the memory data starts to come through in a matter of minutes at the absolute most, in most cases in about 30 seconds, even without rebooting;
Summary
When you follow these simple steps, it’s a few clicks and commands to get XCP-NG Tools up and running on CentOS 7 via XCP-NG Centre. For every virtual machine that you setup, make sure you install XCP-NG Tools to make your life as easy as possible.
by Michael Cropper | Aug 1, 2022 | Developer |
This is one that comes up fairly infrequently and one that always seems to take way more Googling than it should to get a straight answer on this. When in fact, the answer to this question is an extremely simple one, well, usually.
If you are getting regular or intermittent errors with your scripts timing out, count the seconds. Most people are used to having a default timeout with something like Apache Httpd to be 30 seconds. Well, Apache Tomcat likes to play by it’s own rules here and doesn’t quite follow that standard which may leave you scratching your head for a while until you get to the bottom of it.
Here’s what the official Tomcat 8.5 documentation says on the topic;
“The number of milliseconds this Connector will wait, after accepting a connection, for the request URI line to be presented. Use a value of -1 to indicate no (i.e. infinite) timeout. The default value is 60000 (i.e. 60 seconds) but note that the standard server.xml that ships with Tomcat sets this to 20000 (i.e. 20 seconds). Unless disableUploadTimeout is set to false, this timeout will also be used when reading the request body (if any).”
Simple, right?
Basically, just check what you’ve got in your server.xml file and adjust accordingly as it’s not as straight forward as it should be.
But where is that file you may be wondering. Well, by default you’ll find the file at /{TOMCAT_HOME}/conf/server.xml so check there first.
This home directory is going to be different depending on operating system and how Tomcat was installed, so you may have to hunt around for this if you’ve not edited these settings before. Make a note of this file location as it will come in handy over time.
The line you are looking for is;
<!--60 Seconds-->
<Connector URIEncoding="utf-8" connectionTimeout="60000" port="8084" protocol="HTTP/1.1" redirectPort="8443"/>
Simply change the value of the connectionTimeout attribute to what you need, restart Apache Tomcat 8 and re-run the script you were trying to execute which was timing out, things should work now.
Happy config!
by Michael Cropper | Jul 25, 2022 | Developer, IT, Networking |
First of all, networking is a challenge in itself to understand what you want to achieve and how to configure things to make them work. It’s made even harder when basic things that should just work, for some reason don’t due to one reason or another. This blog post is off the back of one of those niggles that was driving me crazy trying to understand why something wasn’t working when it should have been and it turned out the answer was pretty simple when I finally got to the bottom of it.
Before we jump into the details, let’s make sure we’re all on the same page.
What is Ping?
Ping is a command line utility that is designed to test the reachability of a hostname or IP address. In simple terms, it’s a way of your computer saying “hello” to another computer and waiting to see if the other computer responds and says “hello” back – or just ignores you.
To use the ping command, it’s as simple as running either of the following commands via your command line either on Windows or Linux and is often packaged on Linux systems through the iputils package from Yum etc.
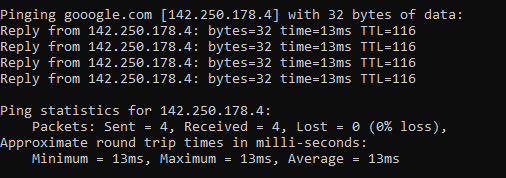
ping google.com
Which will respond as follows if a successful connection is made
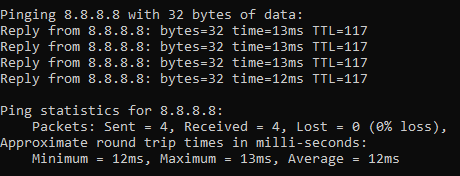
ping 8.8.8.8
8.8.8.8 is the primary IP address of Google’s public DNS system if you’re not aware, with 8.8.4.4 being the secondary IP address. When ping’ed this will respond as follows if a successful connection is made
ping a-website-that-doesnt-exist.com
Here’s what happens when you don’t get a successful response such as when in this example, there is no DNS A Record against that hostname so the hostname cannot be successfully translated into an IP address.

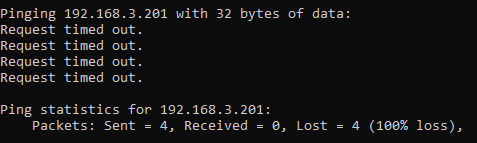
ping 192.168.3.201
Now let’s say that you have a computer on your network that you know exists and you know it is turned on. When you try to ping that IP address, you should receive a successful message as shows above. But in some situations you may get errors such as “request timed out”
This is where things get a little fun trying to debug these things, which we’ll cover off in this blog post.
Ping Summary
The above various examples are what both success and failure messages look like when using the ping command line utility. So you know what to look out for when debugging why ping isn’t working.
What is ICMP aka. Internet Control Message Protocol?
The ping command line utility utilises ICMP, the Internet Control Message Protocol. I’m not going to go into too much detail with this one as we could go down a fairly deep rabbit hole around the Internet Protocol Suite, IEFT and RFCs (Request for Comments) such as RFC1918 which is the protocol that outlines what IP address ranges can be used publicly and which ones are reserved for private usage. We did a blog post covering what RFC1918 is a few years back to help people understand this in a simple way.
Anyhow, to keep things simple ICMP is essentially a supporting protocol as part of the Internet Protocol Suite that is designed to capture success/failure type messages when one host is trying to communicate with another host. Just like in the examples we gave above using the ping command line utility. The reality is that there are a whole host of protocols that the average technical user has never even heard of unless you’re a network specialist such as: TCP, UDP, ICMP, ESP, AH, GRE, EoIP, IPV6, IGMP, PIM, OSPF, SCTP, CARP, PFSYNC. Most people have heard of TCP, some know of UDP, but the rest most people have never heard of and will never need to know anything about.
In reality, ICMP is used by things that are primarily under-the-hood technologies that most people haven’t ever heard of and/or don’t really care about. The exception being command line tools like ping and tracert/traceroute commands which are designed for humans to be using to help with debugging.
Why all of this is important is because ‘a’ firewall along the journey from source to destination could be blocking ICMP traffic which would cause your ping command to fail, when you would expect it to be working.
Understanding the Route of the Network Packets
Now comes the fun part. While things often seem relatively straight forward that Computer 1 wants to talk to Computer 2, the reality is that things under the hood are 100x more complex than this and have so many nuances and company specific configurations that it’s never as straight forward as it should be to debug basic things like this.
Hence why it’s essential that you understand how things are configured under the hood. Unfortunately in my experience in most enterprise organisations, no-one really has a clue how all this actually works and why it works, it just kind of does for the average non-technical user so organisations kind of accept that because it just works, let’s not to prodding it. Ultimately this is an extremely bad thought process to have and when leadership doesn’t question these things, this ultimately causes endless headaches for IT staff doing their daily work because things that should just work often don’t and often require weeks, even months in many cases of time spent on meetings/emails/conversations to ultimately understand what should have really been a 5 minute fix to a problem.
Even worse in some organisations whereby it soon becomes a case of networking/firewall/configuration whack-a-mole whereby people start fiddling with the settings without understanding things fully which solves one problem but creates 10x more which get reported days/weeks later when other things start to break. This stuff is hard, it requires extremely knowledgeable individuals to make informed decisions to configure things well.
Anyhow, back to the main point. You need to understand how things work. How do packets get from Computer 1 to Computer 2 when you are ping’ing the IP address or hostname?
Let’s look at an extremely basic setup and the hops along the way;
- Source Computer sends ping command to Destination Computer
- Source Computer outbound firewall – Does it allow outbound ICMP traffic?
- Network Router/Firewall/Gateway – Does it allow ICMP traffic through from the Source Computer to the Destination Computer?
- Destination Computer inbound firewall – Does it allow inbound ICMP traffic?
And this is where things get even more challenging, since there can be configurations on Windows such as Public and Private networks that you connect to. Let’s be honest, the average user configuring this on their own machines hasn’t got a clue what to select and just randomly click one of the two options. In reality though, depending on what a user clicks on will depend on how Windows behaves and ultimately in this example if Windows response to ping requests or completely ignores them.
Windows Firewall Public and Private Networks
To keep this section focused on the topic at hand, debugging ping requests not working as they should, we’re going to simply take a look at the two common Windows network settings – Public Network and Private Network.
Your device will either have one or both of these options;
- WiFi Network Interface Card (aka. No cable plugged into device)
- Ethernet Network Interface Card (aka. Cable plugged into device)
And each of these within your Windows Network and Sharing Centre will either be configured as a Public Network or a Private Network. By default on Windows, if a NIC (Network Interface Card) is configured to be used as a Public Network, then inbound ping requests will be ignored, whereas if the NIC is configured to be used as a Private Network, then inbound ping requests will be responded to.
Rather annoyingly on Windows, once this initial configuration is done (in most cases incorrectly…) then changing a NIC from Public to Private or vice-versa is not as simple as clicking a button – you have to use Windows Powershell. There should be no reason to do this in 2022, but hey, send your complaints (aka. “feature requests”) into Microsoft to solve this one.
For anyone needing to do this, here’s how to change a Windows network from private to public or how to change a Windows network from public to private;
- Open Windows PowerShell as an Administrator
- Run command:
- Get-NetConnectionProfile
- Which will show you the network type, i.e. either public or private
- Run command:
- Set-NetConnectionProfile –Name “{NAME OF YOUR NETWORK}” –NetworkCategory Private
- Which will set the name of the network to either Private or Public depending on what you type in the above command
- Then when you open your Network and Sharing Centre, you should see that the network has changed from Public/Private to the opposite of what it was previously.
Norton 360 Smart Firewall Blocking ICMP Ping Requests
Another one of those annoying “features” is when Windows based firewall software overrides the default Windows firewall, adding another layer of debugging to a problem. In this case, software such as Norton 360 Smart Firewall essentially takes control of the firewall management rather than Windows out of the box. This is where things can get messy.
End user firewall software, regardless of brand, tend to dumb things down to such as level that they often hide the complexity of the details which are often hard to find in the system. Norton 360 is a prime example of this. By default it blocks inbound ICMP traffic, meaning that if you are trying to ping Computer 2 (with Norton 360 on) from Computer 1, then by default pings will fail. You need to allow ICMP traffic within the Norton 360 Smart Firewall settings to ensure that this traffic can pass through to Windows to respond successfully.
You can see here how deep the settings for this are buried within Norton 360 Smart Firewall, it’s almost impossible to find this without knowing exactly what you are looking for, which 99.9% of users simply haven’t got a clue about.
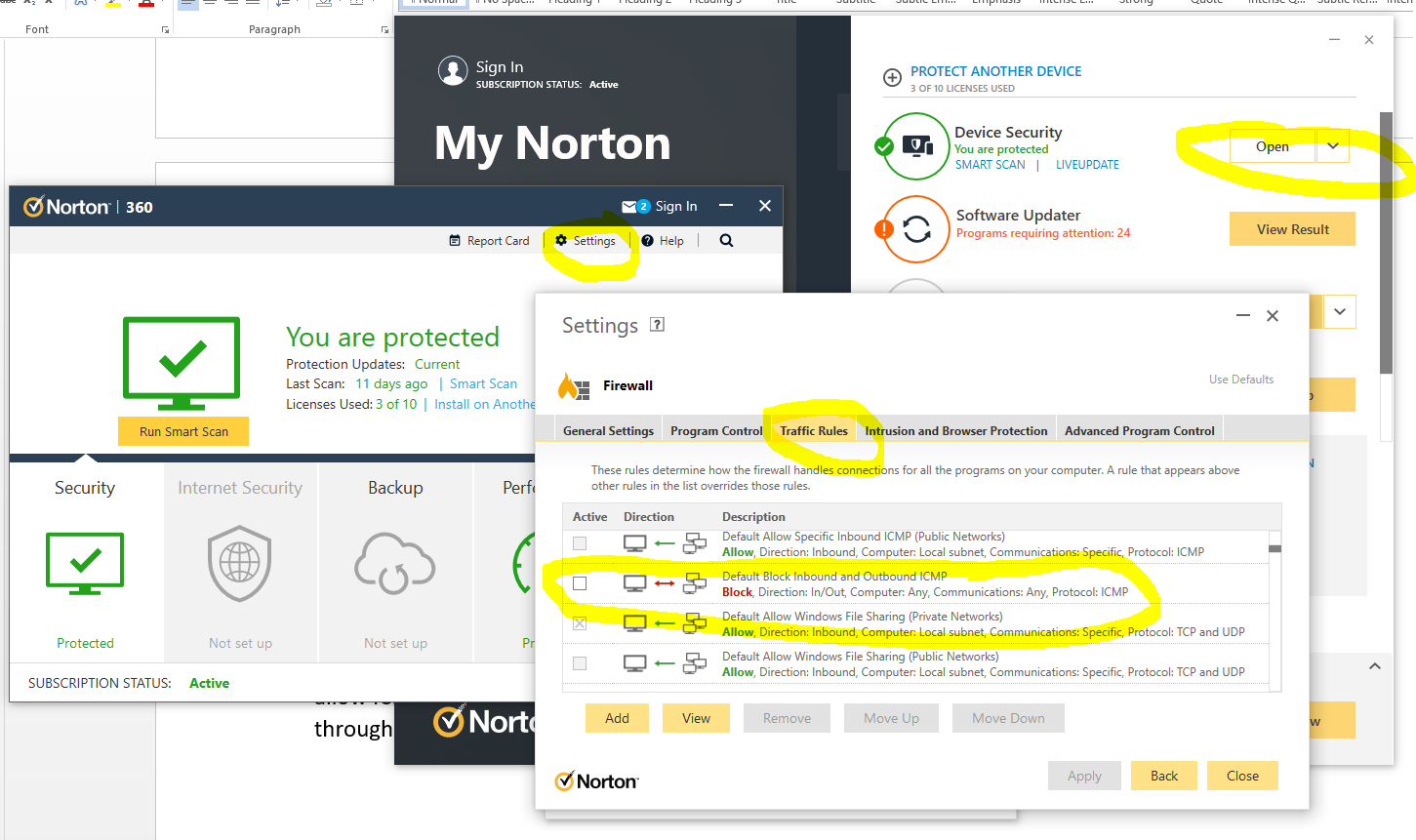
The irony being that there is nothing “smart” about this setup, it’s simply fully of dumb assumptions being made in the guise of security. These kinds of configurations are an absolute pain to deal with as they are never well documented out of the box about what is the default configuration, which ultimately results in people digging and digging and digging to get to the root cause of why something that should be working isn’t working. Hey, the joys of IT I guess. It does annoy me though around all these assumptions that are made by software vendors to try and “help”. The best help they could give is write better documentation and/or build their software in a way that caters for different types of users from basic to power users and documentation that helps even the most computer illiterate individual understand what they need to configure. Most companies don’t seem to get this basic concept though, unfortunately.
Summary
I hope that this blog post has given you some guidelines and thoughts about how to debug and troubleshoot issues when commands like ping and tracert/traceroute aren’t quite working as expected. What you’ve hopefully picked up is that these things aren’t straight forward to debug.
The best advice I can possible give is to be methodical at every step along the way. Aim to understand every hop along the journey, and confirm for every hop that traffic is successfully leaving the hop and successfully arriving at the next hop along the way.
It’s not straight forward and requires an exceptional understanding of the underlying infrastructure, which often isn’t easily accessible particularly within enterprise organisations. It’s not easy debugging these kinds of things with every hand/arm/limb/sense tied behind your back.
by Michael Cropper | Jul 3, 2022 | Developer |
Webhooks are a very interesting topic, but they are often misunderstood by both technical and non-technical people alike. The reason they are misunderstood is often because depending on who you ask or what system you are looking at, each often has their own slight variance on what they actually are and how they are used.
I often head phrases such as “a Webhook is just an API isn’t it?” Well, no, not quite. And “Why do we need Webhooks when we can just poll a system for changes?” Webhooks are a complex topic to understand well, but fundamentally they are actually really basic things.
A Webhook is simply a term used for when something happens in a Source System that it will send a notification or data to a Destination System. Conceptually, there is nothing much more to it than that.
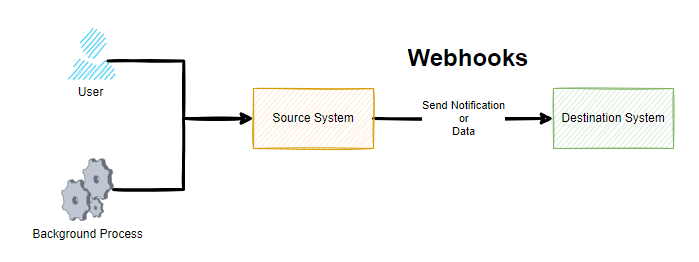
Sounds simple when you put it like this, right? Well, yes, and it is that simple at least at the conceptual level. As always, the devil is in the detail. Webhooks are commonly described as user-defined callbacks.
As you can see in the above diagram, whenever either a User or a Background Process / System Event happens, this means that the Source System sends a notification or data to a destination system. But how you may be thinking. Well, we’ll come onto that in a little while. For now, just keep this basic concept in your mind for what Webhooks are.
When Should I Look at Webhooks?
There are many reasons you want to look at Webhooks and this type of technology, often it is when you want to something to happen in one system off the back of something happening in another system.
For example, some common use cases of Webhook technology is when a customer on an ecommerce website makes a purchase using a payment gateway. When this happens, the payment gateway needs to inform your website that the payment was either successful or it failed as you want to make sure the customer has paid before you go sending the goods out to them. Or another common use case is when you have a master system of record for certain types of data and you want to ensure this data is replicated in another system which is quite common in enterprise organizations to ensure a user doesn’t have to log in to 10x different systems to do their day job.
You may also want to start to look at Webhook technology when you are integrating systems together or you may have a legacy integration in place with either CSV files flying around and/or what I like to call Nagging Integrations, whereby System A will continually poll System B asking if there has been any changes that it needs to be aware of. These types of integrations are extremely inefficient, particularly if data only changes say once per hour and your integration is asking if anything has changed once per minute. These types of integrations are wasteful.
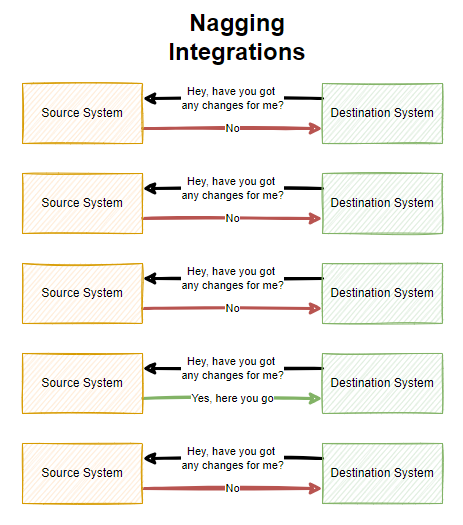
As you can see above, there is a lot of waste with Nagging Integrations which poll a system on a regular frequency. All of this needless additional load can result in your applications being less performant and require more infrastructure resource to power because of this inefficiency which can have a cost implication.
Why Webhooks are Awesome
Many legacy integrations are simply either too slow, too dumb or a mixture of both. This is why Webhook technologies are so awesome. Webhooks are real time data and notification transfers to get data moving throughout an organization to where it needs to be. That means, no more batch jobs or overnight data loads slowing an organization down.
With technology first systems, you will often find that Webhook technologies come out of the box and are configurable to what you need so you can design your data flows efficiently throughout your enterprise organization. The reality is though, many systems aren’t built in this modern way to enable this capability, so don’t expect everything to support this type of technology.
I should also clarify, that Webhooks are a concept, it’s not something you can purchase and plug in to your existing systems as they need to be built into systems from the core. We’ll come on to this bit a little later in this blog post.
Who Uses Webhooks?
I’ve already mentioned a few example earlier around some common use cases for Webhooks being either ecommerce and payment gateway related, or getting data moving around an enterprise organization in real time. You’ll find that a lot of SaaS (Software-as-a-Service) companies will have some form of Webhook technology baked into them.
In some cases, there are even entire business models and SaaS companies that have been built to piggy back off this technology. Companies such as IFTTT (If This Then That) and Zapier have a suite of tools in their systems which are powered through Webhook technologies under the hood to get notifications and data moving to where it should be.
Where Can I Use Webhooks?
As for where you can use Webhooks, well, this all depends on the software and systems that you are working with. In my experience, the majority of historical legacy system simply won’t have any kind of Webhook type technology to use for integrations. You’ll often be lucky if they have APIs available in some way or another.
You tend to find that Webhook technology will sit in the bit companies, the SaaS tech first companies. The bigger the company you tend to find that the Webhook technology is more configurable within their system whereas some systems only have basic levels of customization in place.
It all depends on your use case. When you want to look at getting data moving from one system to another, Webhooks are often the first choice due to how efficient they are. So do your research on the systems you are using to understand their capabilities.
If you look at modern SaaS applications that technology first organisations use on a daily basis, all of these come with Webhook technology built in;
- Stripe
- Paypal
- GitHub
- Jira
- Salesforce
- Microsoft Business Central (aka. Microsoft Navision in older terminology)
- SAP
- Microsoft Teams
To name just a very small handful examples that you are probably familiar with. What is interesting to note is that even between the above systems there are often slight differences in terminology and capabilities depending on your individual use case.
How do Webhooks Work?
So now, onto the good bit for how Webhooks work. All of the above has been explained on a fairly high level of what Webhooks are and how they work. Now, we’re going to take a deeper dive into Webhooks so it’s clear how they work as they are no-where near as simple under the hood.
To help keep this bit as simple as possible, let’s break this down into a couple of core sections;
- Source System
- Destination System
Fundamentally Webhook technology uses the Publish-Subscribe architectural design pattern, whereby one system publishes something and another system(s) then subscribe to that event so they get notified when something happens that they care about.
Google actually created PubSubHubbub (Best name ever for a platform!) quite a few years ago with the aim to synchronize content from many different RSS feeds into a handy platform for content. It never really took off unfortunately, likely due to the demise in the use of RSS feeds generally as social media platforms pretty much got the attention of users. So Google open-sourced their implementation of the concept Webhook technology in 2017 which is called WebSub and designed it as a protocol for communication as a way to standardize how these things work.
What is important to note though, Webhooks are a concept of sending data from one system to another in a real time and even driven way. PubSubHubbub and WebSub are just one implementation of this, and in my experience, most software vendors create their own implementations of Webhook technology based on the specific details of what they want to achieve and how they want to go about doing it. In practice, there is no one size fits all so companies often build these things how they see fit, some of which are configurable and others aren’t etc.
To extend the original diagram from earlier, this is more like what a Webhook really is when you look at it end to end;
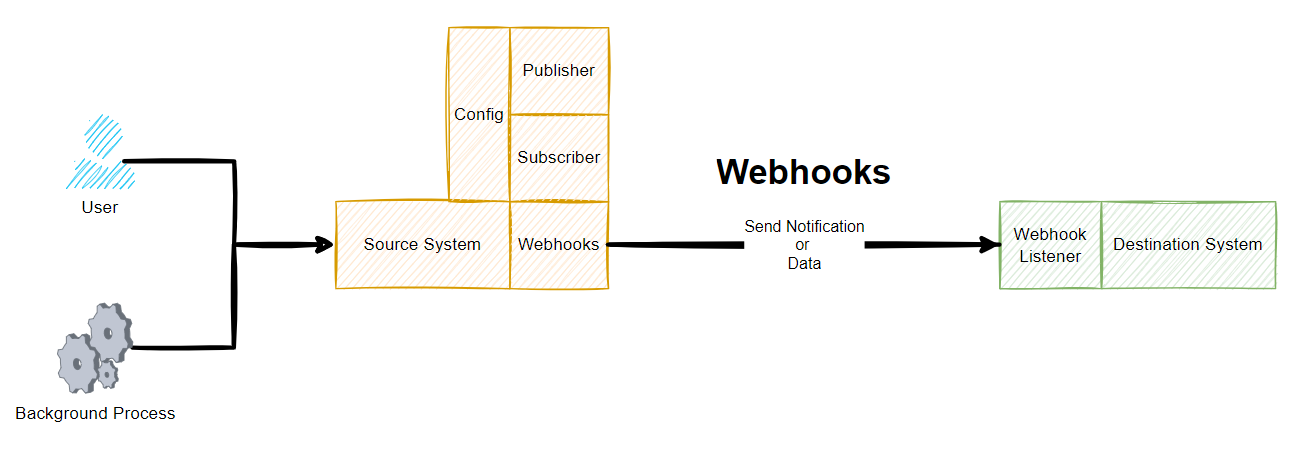
Source System Webhooks
Ultimately a source system is just a bunch of code under the hood that teams of software engineers have been crafting for many years to build the product that you see and use today. Fundamentally these systems have a core data model behind the scenes too. To keep things simple as an example, imagine the source system stores basic data about a company in different related data objects;
- Company
- Company Stores
- Company Contacts
The next step is to ensure the system is coded in a way that can ensure that when data changes for these different data objects that an event is captured, aka. published, which can then be subscribed to by another system.
Depending on the system in use, this may be a hard coded approach to sending data to another system and this can be absolutely fine in many scenarios despite the negative connotations with the word hard coded. In more advanced technology first SaaS platforms, this kind of thing generally has a user interface designed to allow a user of the system to configure what they want to do and when etc. These two different approaches involve vastly different amounts of effort to build, so in many cases this is an evolution of time to get the system more configurable and less hard coded, but this is all dependent on use cases.
Then when it comes to the implementation, there are additional nuances to consider. Do we queue the messages, or do we send and forget in real time? What about retries if a message doesn’t get through, do we care if something fails or do we implement a FIFO (First In First Out) message queue to ensure we have the visibility that something has been successfully sent etc.
What about logging, when things go wrong we need to understand why etc. Even with some of the big players mentioned earlier, not all of these concepts are built into their systems yet that can be accessed by a user.
What about the order of execution, is that important? Well, yes in a lot of cases it is to ensure that the updates are processed in the correct manner and the latest update is an accurate reflection of the state of the data. In other cases, the order of execution may not be important at all as it is a simple notification that something happened and when you click through to see the details that has the most up to date information. All of these things need to be considered.
Destination System Webhooks
This is the part that is often forgotten when it comes to Webhook technologies. Just because a Source System can send out a message to a Destination System this isn’t the end of it. What does the Destination System do with the message? Does it even understand the message? This is where things can get complex.
Fundamentally a Webhook is essentially built up of the basic building blocks;
- URL – Where the message should be sent
- Payload – What the message is, usually sent in JSON
Then it is up to the Destination System what to do with this message. And this is where the other half of the complexities lie. This is what is generally referred to as a Webhook Listener. There is no real difference between this terminology and that of a standard API which is basically doing the same thing when data is sent into it using a POST Request.
What the Destination System chooses to do with this message is up to itself. What HTTP Status Code should be sent?
- 200 OK
- 400 Bad Request (aka. I’ve no idea how to interpret your message)
- 401 Unauthorized (aka. you are not authenticated so you cannot access the system)
- 403 Forbidden (aka. you are authenticated but you don’t have permissions to do what you are trying to do)
Ultimately how the Destination System behaves determines if the Source System is happy that the message has got through or not.
Summary
Overall, I’m sure you can see that while Webhooks seem fairly straight forward conceptually, when you get under the hood they can be extremely complex beasts. This complexity from many of the big SaaS providers is often abstracted through the use of marketplaces and plugins where apps or connectors or whatever they like to call them do the translation between the systems to ensure the right message gets through when it should. And likewise there are often user configurable features within modern systems that allow you to easily add/edit/remove configured Webhooks to suit your needs at that point in time. Some systems are more/less configurable than others, so keep this in mind.
Webhook technologies are seriously powerful tools when implemented well. The reality is that they are difficult to build when you are designing a platform that requires this technology embedded into it. As a user of Webhook technologies, you’ll find this technology extremely beneficial in a wide range of use cases. As a software engineer involved with designing and building the system architecture for Webhook technologies, well, this needs a lot of thought to get right and to continually evolve to meet the ever growing expectations from users.
by Michael Cropper | May 2, 2021 | Amazon Web Services AWS, Client Friendly, Developer, Technical |
Amazon Linux (aka. Amazon Linux 1) was straight forward to get Let’s Encrypt setup, it was a breeze and the documentation wasn’t too bad. I don’t know why Let’s Encrypt support for Amazon Linux 2 just isn’t where it needs to be, given the size and scale of Amazon Linux 2 and the fact that Amazon Linux is now an unsupported operating system. It’s likely because Amazon would prefer you to use their AWS Certificate Manager instead, but what if you just want a Let’s Encrypt certificate setting up with ease. Let’s take a look at how you get Let’s Encrypt setup on an AWS EC2 instance that is running Amazon Linux 2 as the operating system/AMI.
Assumptions
We’re assuming you’ve got Apache / Apache2 installed and set up already with at least one domain name. If you are using Nginx or other as your Web Server software then you’ll need to tweak the commands slightly.
How to Install Let’s Encrypt on Amazon Linux 2
Firstly, we need to get the Let’s Encrypt software installed on your Amazon Linux 2 machine, this is called Certbot. For those of you looking for the quick answer, here’s how you install Let’s Encrypt on Amazon Linux 2 along with the dependences;
yum search certbot
sudo amazon-linux-extras install epel
sudo yum install python2-certbot-apache
sudo yum install certbot-apache
sudo yum install mod_ssl python-certbot-apache
sudo certbot --apache -d yum-info.contradodigital.com
For those of you looking for a bit more information. There are a few fairly undocumented dependencies to get this working. So to get started you’ll want to install the dependencies for Let’s Encrypt on Amazon Linux 2 including;
- Epel, aka. The Extra Packages for Enterprise Linux, from the Amazon Linux Extras repository
- Python2 Certbot Apache using Yum
- Certbot Apache using Yum
- Mod_SSL, Python Certbot Apache using Yum
As it was a bit of a pain to get this configured, I’m fairly sure one of the above isn’t required, I just can’t recall which one that was.
How to Configure Let’s Encrypt on Amazon Linux 2 for a Domain
So now you’ve got Let’s Encrypt installed on Amazon Linux 2, it’s time to generate an SSL certificate for your domain that is hosted. For the purpose of simplicity we’re going to assume you’re running very basic setup such as www.example.com/HelloWorld.html. There are other nuances you need to consider when you have a more complex setup that are outside of the scope of this blog post.
sudo certbot --apache -d yum-info.contradodigital.com
What you’ll notice in the above is that we’re using Certbot and telling it that we’ve got an Apache Web Server behind the scenes and that we want to generate an SSL certificate for the Domain (-d flag) yum-info.contradodigital.com.
Simply run that command and everything should magically work for you. Just follow the steps throughout.
Summary
The above steps should help you get setup using Let’s Encrypt on Amazon Linux 2 without much fuss. Amazon Linux 2 really does feel like it has taken a step back in places, Amazon Linux 1 had more up to date software in places, and easier to work with things like Let’s Encrypt. But hey. We can only work with the tools we’ve got on the AWS platform. Please leave any comments for how you’ve got along with installing Let’s Encrypt and getting it all set up on Amazon Linux 2, the good, the bad and the ugly.
by Michael Cropper | Apr 29, 2021 | Amazon Web Services AWS, Client Friendly, Developer, Technical |
AWS. With great power comes with great responsibility. AWS doesn’t make any assumptions about how you want to backup your resources for disaster recovery purposes. To the extent that they even make it easy for you to accidentally delete everything when you have zero backups in place if you haven’t configured your resources with termination protection. So, let’s think about backups and disaster recovery from the start and plan what is an acceptable level of risk for your own setup.
Risk Appetite Organisationally and Application-ally
OK, that’s a made up word, but you get the gist. You need to assess your appetite to risk when it comes to risk, and only you can do this. You have to ask yourself questions and play out roll plays from “What would happen if a single bit of important data got corrupted and couldn’t be recovered on the Live system?” all the way through to “What would happen if the infrastructure running the Live system got hit by a meteorite?”. Then add a twist into these scenarios, “What would happen if I noticed this issue within 10 minutes?” through to “What would happen if I only noticed this issue after 4 days?”.
All of these types of questions help you to assess what your risk appetite is and ultimately what this means for backing up your AWS infrastructure resources such as EC2 and RDS. We are talking specifically about backups and disaster recovery here, not highly available infrastructures to protect against failure. The two are important aspects, but not the same.
As you start to craft your backup strategy across the applications in your corporate environment and tailor the backup plans against different categories of applications and systems into categories such as Business Critical, Medium Risk, Low Risk etc. then you can determine what this looks like in numbers. Defaults for frequency of backups, backup retention policies and such like.
How to Backup EC2 and RDS Instances on AWS Using AWS Backup
To start with the more common services on AWS let’s take a look at how we back these up and what types of configurations we have available to align out backup strategy with the risk appetite for the organisation and the application itself. The specific service we’re interested in for backing up EC2 and RDS instances on AWS is creatively called….. AWS Backup.
AWS Backup allows you to create Backup Plans which enable you to configure the backup schedule, the backup retention rules and the lifecycle rules for your backups. In addition, AWS Backup also has a restore feature allowing you to create a new AWS resource from a backup so that you can get the data back that you need and/or re-point things to the newly restored instance. Pretty cool really.
The first thing you want to do to get started is to create a Backup Plan. Within the creation process of your Backup Plan, you can configure all the items mentioned previously. Usually we’d walk through the step by step to do this, but really you just need to walk through the settings and select the options that suit your specific needs and risk appetite.
Below is a basic Backup Plan that is designed to run daily backups with a retention policy of 35 days, meaning we have 35 restoration points. You’ll also notice that instead of doing this for specific named resources, this is backing up all resources that have been tagged with a specific name.
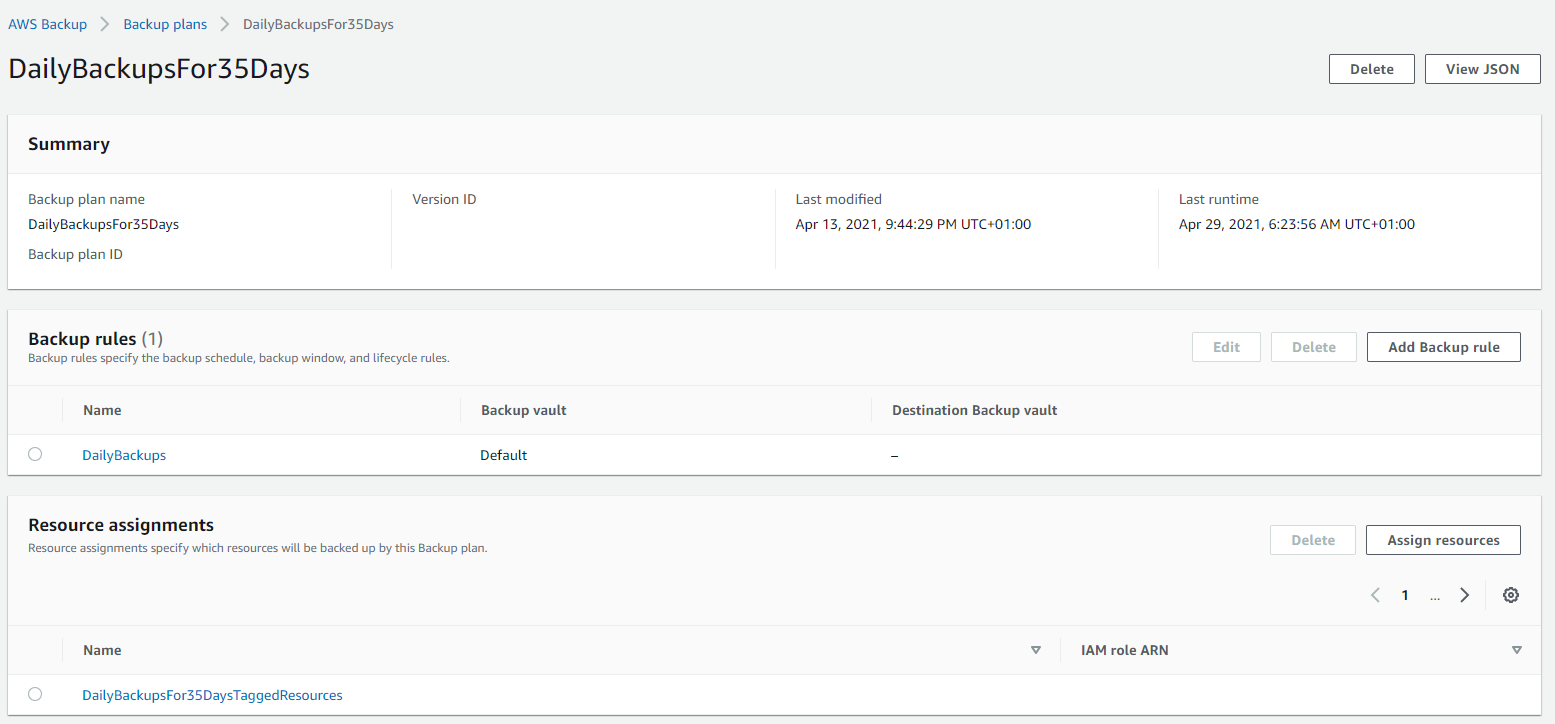
Tagged Resources;
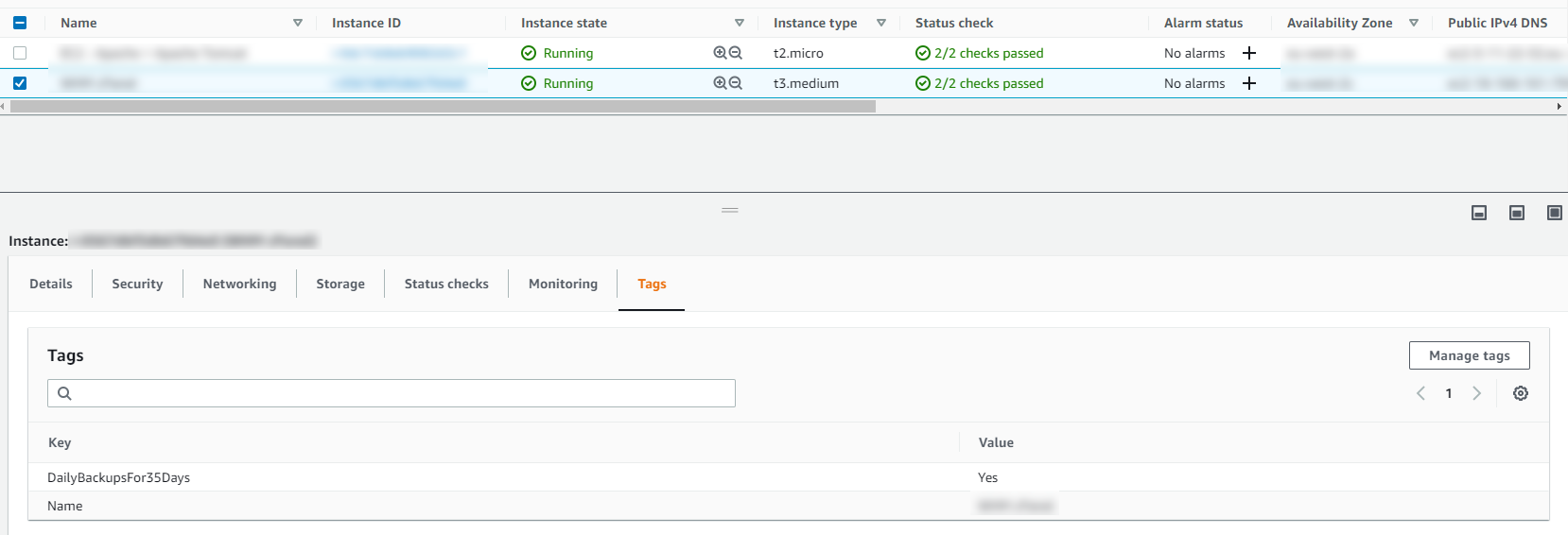
The tagged resource strategy using AWS Backup is an extremely handy way of managing backups as you can easily add and remove resources to a Backup Plan without ever touching the Backup Plan itself. Naturally you need a proper process in place to ensure things are being done in a standardised way so that you aren’t constantly hunting around trying to figure out what has been configured within AWS.
Running Backups
Once you have your Backup Plans in place, you can then start to see easily the backups that have been running, and most importantly if they have been successful or if they have failed.
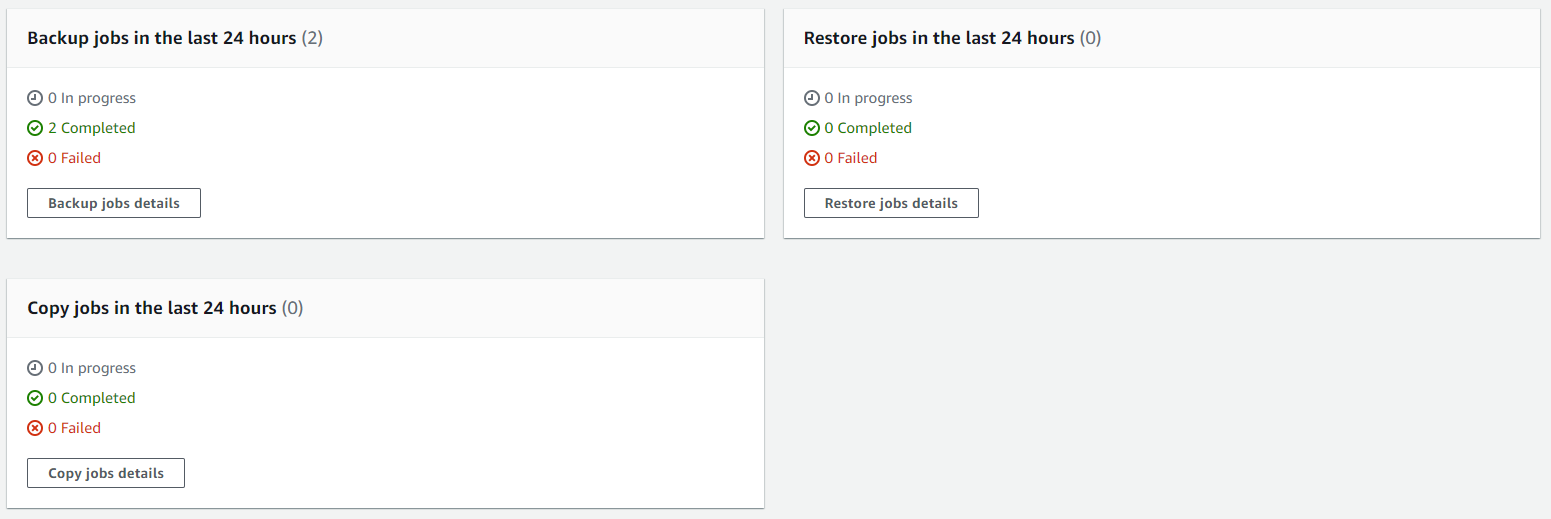
Then you can drill into the details and see all of your restoration points within your Backup Vault and ultimately this is where you would restore your backups from if you ever need to do that;
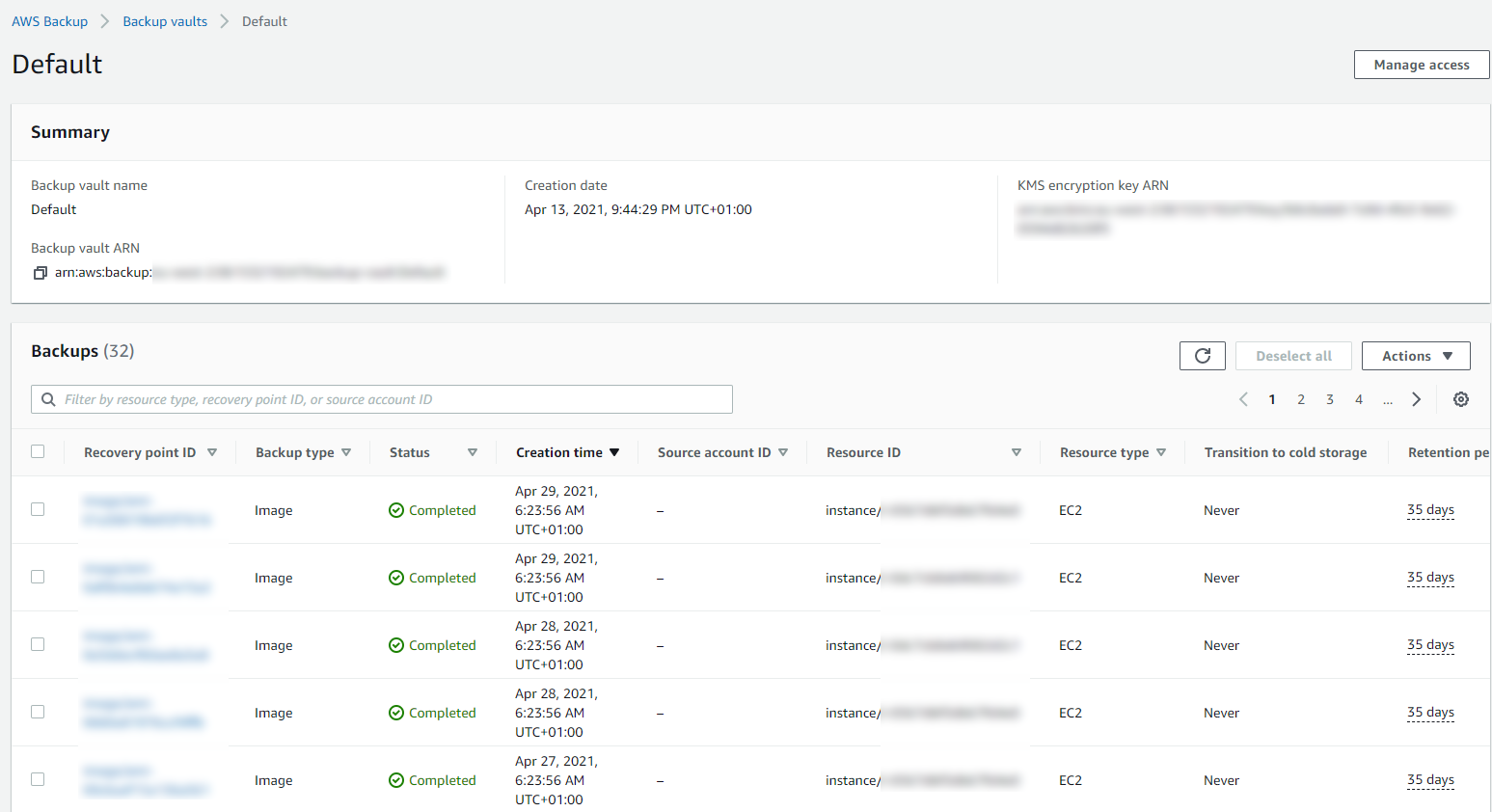
Summary
Hopefully that’s a whistle stop tour of how to backup your AWS infrastructure resources such as EC2 and RDS on AWS using AWS Backup. The best advice I can give when you are implementing this in the real world is that you need to truly understand your IT landscape and create a backup strategy that is going to work for your business. Once you have this understood, clicking the right buttons within AWS Backup becomes a breeze.
Don’t do it the other way round, just creating random backups that don’t align with the business goals and risk appetites. You will end up in a world of pain. No-one wants to go reporting to the CEO….. IT: “Oh we only have backups for 7 days.” ….. CEO: “What?!?!?! We are legally required to keep records for 6 years! WTF!”. You get the gist.
This can be quite an enormous topic to cover, so here’s some further reading if you want to know more;
by Michael Cropper | Apr 27, 2021 | Client Friendly, Developer, Technical |
So this isn’t quite as straight forward as it probably should be and the documentation from AWS is the usual, not great. So let’s cut through the nonsense and take a look at what you need to do so that you can quickly and easily get your DNS Zone Files and DNS Records migrated.
Assess Your Current DNS Provider, Zone Files, Domains and Nameserver Configurations
The first things you want to do before you start any kind of migration of your DNS over to AWS Route53 is the plan. Plan, plan and plan some more. Some of the nuances I came across with a recent DNS migration piece of work from DNS Provider X to AWS Route53 included some niggles such as vanity nameservers. The old DNS provider had things configured to ns1.example.com and ns2.example.com, then domain1.com and domain2.com pointed their nameservers to ns1.example.com and ns2.example.com which was quite a nice touch. This doesn’t quite work on AWS Route53 and I’ll explain that in a bit more detail in a moment. Another niggle that we came across that you need to plan properly and that is to make sure you have absolutely everything documented, and documented correctly. This needs to include for every domain at an absolute minimum things such as;
- Domain name
- Sub-Domains
- Registrar (inc. login details, and any Two Factor Authentication 2FA steps required)
- Accurate Zone File
The vast majority of people just have a Live version of their DNS Zone Files, which in itself is risky because if you had an issue with the DNS Provider X and you had no backup of the files, you could be in for a whole world of pain trying to re-build things manually in the event of a critical failure.
How AWS Route53 Manages Hosted Zones
So back to the point I mentioned earlier around vanity nameservers and why this doesn’t quite work in the way the old DNS Provider X worked. When you create a new Hosted Zone within AWS Route53, Amazon automatically assigns 4x random nameservers of which you can see an example below;
- ns-63.awsdns-07.com
- ns-1037.awsdns-01.org
- ns-1779.awsdns-30.co.uk
- ns-726.awsdns-26.net
What you will instantly notice here is that there are a lot of numbers in those URLs which should give you an idea of the complexity of the nameserver infrastructure behind the scenes on the Route53 service. What this also means is that because these nameservers are automatically generated you can’t configure two Hosted Zones to use the exact same nameservers to get the similar vanity nameserver setup explained earlier.
The reality is, this approach while is fairly common for complex setups, the majority of standard setups this isn’t an issue for. If you want to get vanity nameservers set up on AWS for a single domain, i.e. ns1.domain1.com and ns1.domain2.com etc. then you can do this if you wish.
Export Zone Files from your Old DNS Provider
The first step of this process is to export your Zone Files from your old DNS provider. What you will find from this process is that ever provider will export these slightly differently, and this highly likely won’t be in the format that Route53 needs when you import the Zone Files.
Create a Hosted Zone in Route53
This step is straight forward, just click the button.
Importing Zone Files to your Hosted Zone
As such, it’s time to prepare your Zone Files to be able to be imported into Route53 successfully. The format you need for your zone file import is as follows;
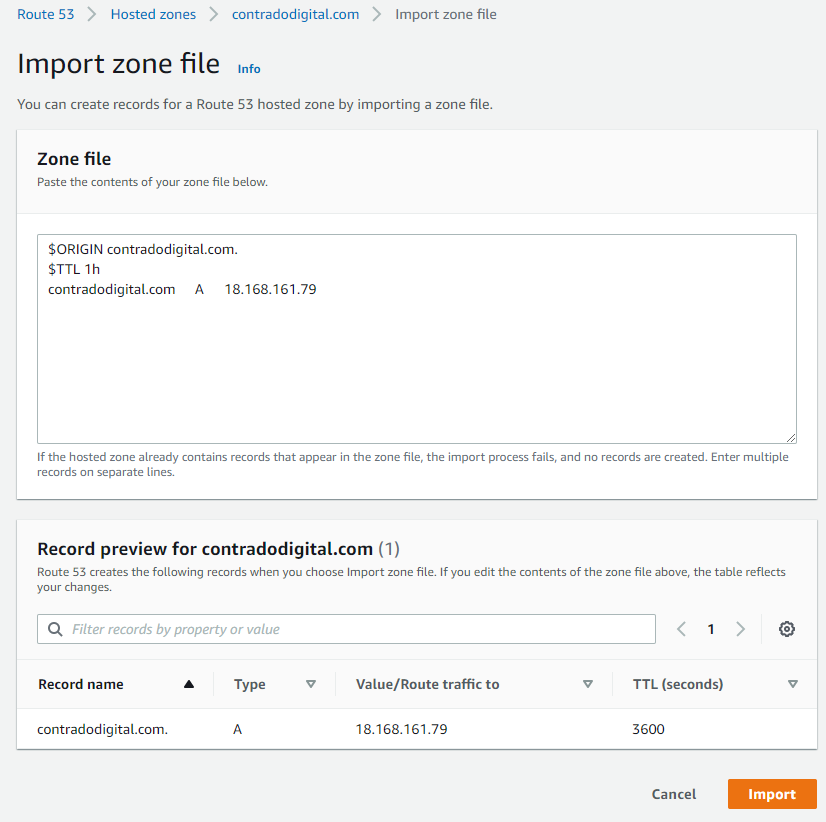
$ORIGIN contradodigital.com.
$TTL 1h
contradodigital.com A 18.168.161.79
Notice the couple of additional lines you need to add in which likely won’t be included from your export from your old provider. The above is just a very basic set of DNS entries. The reality is you will likely have 10 – 50+ DNS entries per domain depending on the complexity of your setup. One to keep an eye out on is that you may find certain record types don’t quite import seamlessly. Just a few niggles that I came across doing this included;
- MX records required a 10 included, i.e. contradodigital.com MX 10 contradodigital-com.mail.protection.outlook.com
- DKIM (TXT) and SPF (TXT) records had to be re-generated and imported manually as the format just didn’t quite work for the automatic import for some reason.
And I’m sure you’ll come across a few issues along the way that I haven’t mentioned here.
Summary
Hopefully this guide on how to import Zone Files into AWS Route53 helps to clarify some of the niggles around using the Zone File Import feature. To reiterate around this process when you are doing this in a real situation, make sure you plan this properly, have clear checklists and processes that you can methodically work through to ensure things are working as you do them. These types of changes can have a significant disruption to live systems if you don’t implement these things correctly.
by Michael Cropper | Apr 27, 2021 | Client Friendly, Developer, Technical |
We’ve got a lot of complex topics to cover here, so for the sake of simplicity we’re only going to touch on the really high level basics of these concepts to help you understand how all these different pieces of the puzzle are connected together. When you’re first getting started in the world of IT, it’s often a bit of a puzzle how all these things are plugged together under the hood which can cause a lot of confusion. By knowing how things are plugged together, i.e. how the internet works, you will have a significantly better chance of working with existing setups, debugging problems fast, and most importantly building new solutions to bring your creative ideas to life.
Firstly, let’s get some basic terminology understood;
- Registrar = This is where you purchased your domain name from, i.e. example.com
- Nameservers = This is the where the authority starts for your domain, i.e. it’s the equivalent of “tell me who I need to talk to who can point me in the right direction to get to where I want to go”. It’s the authority on the subject whose opinion on the matter is #1.
- DNS = This is the gate keeper to determine how traffic into your domain flows to where it needs to go. Think of your DNS like Heimdall from the Thor movies. You configure your nameservers to act in a way that you want, i.e. requests from www.example.com, should ultimately route to server IP address, 1.2.3.4, so that you don’t need to go remembering a bunch of IP addresses like a robot – or in the Heimdall world, “Heimdall…” as Thor screams in the movies, and he is magically transported from Earth to his home world of Asgard. Likewise, if Loki wants to visit a different planet, he just asks Heimdall to send him there and the magic happens. DNS can appear like magic at times, but it’s actually really simple once you understand it. DNS is a hard concept to explain simply, we’ll do another blog post on this topic in more detail another time. Hopefully this basic comparison helps you to at least grasp the topic at a high level.
- Servers = This is where things get fairly messy. This could be a physical piece of hardware that you can touch and feel, or could be a virtualised system, or visualised system within a virtualised system. There are multiple layers of virtualisation when you get down to this level. Although it’s not that important for the purpose of this blog post. Ultimately, all we care about is that the traffic from www.example.com, or something-else.example.com, gets to where it needs to when someone requests this in their web browser.
As mentioned, this is a difficult concept to explain simply in a blog post as there are so many different considerations that need to be made. But hey, let’s give it a go, with a basic diagram. There are elements of this diagram that have been simplified to help you understand how the different bits fit together.
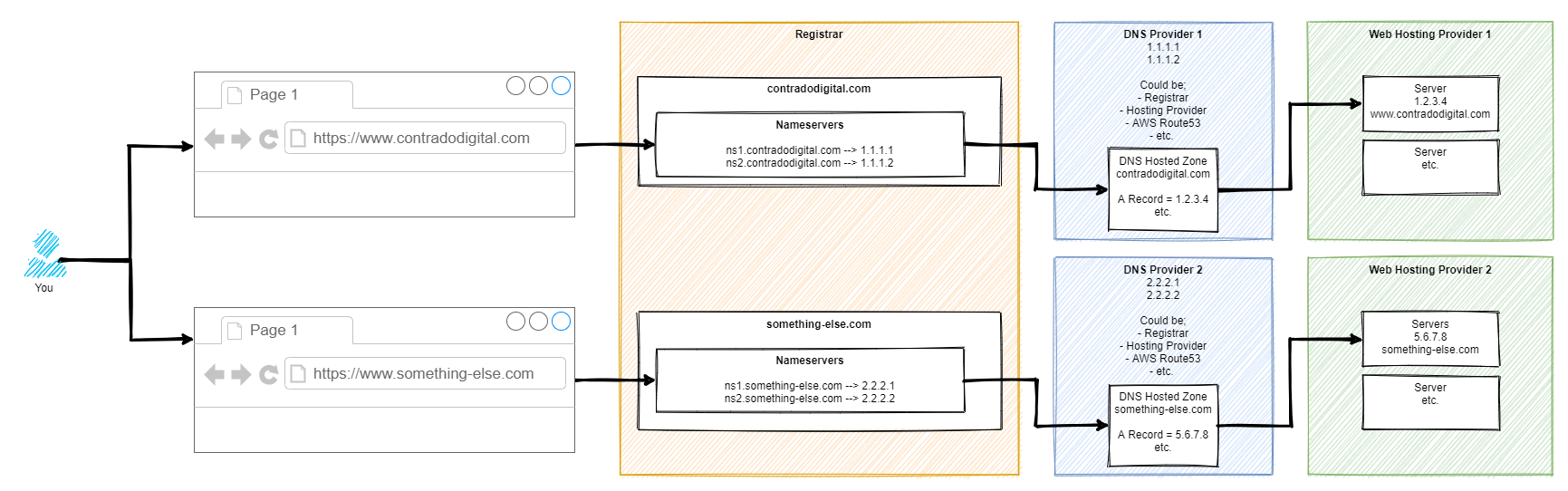
So here’s how it works step by step. For those of you who are more technical than this blog post is aimed at, yes there are a few steps in between things that have been cut out for simplicity.
Step 1 – Type Website Address into Web Browser
This step is fairly basic so we’ll skip over this one.
Step 2 – Web Browser Asks for Authoritative Nameserver for Website
This part is very complex in the background, so we’re not going to delve into these details. For the purpose of simplicity, ultimately your web browser says “Give me the name servers for contradodigital.com”, and ‘the internet’ responds with, “Hey, sure, this is what you’re looking for – ns1.contradodigital.com and ns2.contradodigital.com”.
As with all hostnames, they ultimately have an IP address behind them, so this is what then forwards the request onto the next step.
Step 3 – DNS Provider with Hosted Zones
A Hosted Zone is simple something such as contradodigital.com, or something-else.com. Within a Hosted Zone, you have different types of DNS Records such as A, AAAA, CNAME, MX, TXT, etc. (that last one isn’t an actual record, just to confirm 🙂 ). Each of these record types do different things and are required for different reasons. We’re not going to be covering this today, so for simplicity, the A Record is designed to forward the request to an IP Address.
So your DNS Provider translates your request for www.contradodigital.com into an IP address where you are then forwarded.
Step 4 – Web Hosting Provider Serves Content
Finally, once your web browser has got to where it needs to get to, it starts to download all the content you’ve asked for from the server on your web hosting provider to your web browser so you can visualise things.
This part of the diagram is so overly simplified, but it is fine for what we are discussing. The reality of this section is that this could quite easily be 10-20 layers deep of ‘things’ when you start to get into the low level detail. But that’s for another time.
If you want to get a feel for how complex just part of this area can be, we did a blog post recently explaining how Your Container Bone is Connected to Your Type 2 Hypervisor Bone.
Summary
Hopefully this blog post has given you a good understanding of how your Registrar, Nameservers, DNS and Servers are connected together under the hood. When you truly understand this simple approach, play around with a system that isn’t going to break any live environment, so you can start to test different types of configurations along the way to see how they behave. If you don’t know what you are doing, do not play around with these things on a Live system as you can do some real damage if you get things wrong which can result in your services being offline for a significant period of time.