by Michael Cropper | Jul 8, 2020 | Developer |
Oh, the joys of networking… A topic that very few people like and/or fully understand. So thought it was about time we covered some of these topics to help clarify common misunderstandings and to help people easily understand networking in general. For simplicity, I’m going to stick with IPv4 IP addresses for now and completely ignore IPv6 IP addresses. I’m also going to completely ignore the concept of CIDR blocks and address ranges within this blog posts to just purely focus on the core concepts.
What are Public and Private IP Addresses
Simply put, there is nothing really different, they are just an IP address, right? Well, kind of yes and no. It all comes down to routing, i.e. how your request from A ultimately reaches B. In simple terms, anything starting with any of the following numbers are classified as ‘Private’ IP addresses;
- 10.0.0.0/8 (10.x.x.x)
- 172.16.0.0/12 (172.16.x.x)
- 192.168.0.0/16 (192.168.x.x)
So thinking through the routing concept again of how you get from A to B. This depends on where A and B ultimately live. Remember, every IP address ultimately routes through to a physical server (i.e. computer) which lives somewhere in the real world – whether that is in your back bedroom or in an Amazon data centre somewhere in the world.
How does Routing Work for Private Address Ranges
So now we understand that an IP address starting with, 10., 172. Or 192. Is classified as a private address – what does this actually mean? As mentioned, ultimately an IP address routes through to a physical piece of computer equipment, so why do we care if an IP address is a public IP address (i.e. not starting with these numbers) or a private IP address? Well, it all comes down to routing, i.e. how the message gets from A to B.
For the purpose of this example, let’s keep things super simple. In the scenario whereby you have a personal home laptop or computer. You likely have a home router+modem that has been provided to you from your internet service provider (ISP), the people who provide the internet connection to your home.
To visualise this, if you open the web browser on your home computer and type the following into the address bar of your favourite browser (Chrome, right?), 192.198.0.1 – you’ll likely be presented with the administrator console for your router+modem that has been provided from your ISP. This allows you to login (likely with a super-secure username/password of admin/admin…) so you can then see all of the devices that are connected to your local network, aka. private network. You’ll likely see your laptops, computers, tablets, mobile phones, smart TVs and IoT devices all connected to your local network either via wired or wireless connections. Cool right?
Ok, so back to the point about routing and private VS public IP addresses.
Simply put, whenever a device that is on your local network attempts to connect to another device, your router decides where to … route … the connection to. For example, if you are on your local network and you are trying to access another device on the local network, the route that the connection from A to B (which often has many steps involved, not just the one) never actually leaves your premises to go the internet for help. Whereas if you were accessing a public IP address (aka. an IP address starting with anything other than the three mentioned) then your request would go out into the internet to find the physical computer hardware that is at this address.
The reality is for public IP addresses is that these are often a single IP address that can have thousands of virtual and/or physical machines sitting behind them, which is where NAT comes in – but we’ll ignore that for the purpose of simplicity. We’ll cover that another time. For the purpose of this blog post, we’ll assume that we’re just accessing different systems based purely on IP addresses and not friendly names such as server-x.contradodigital.com.
What About Modern Routing?
The reality is that with most modern routing this isn’t based on IP address alone, it’s often based on a combination of IP Address and Hostname (aka. the name you type into the browser). What this means is that whenever you type in a hostname into the browser, this ultimately resolves to an IP address that knows how to handle your request and ultimately get you to the destination physical/virtual computer that can serve you the information you need. Thankfully, you never need to worry about that as a user. But from a configuration perspective this is hugely important as if you are designing this setup, you need to be able to configure how to handle incoming requests. That is outside of the scope of this blog post though as this gets into the world of NAT, proxies and reverse-proxies.
Size of Private Networks
Things are a little more nuanced by the three core private IP ranges as they each support a different number of devices connected to that network. Remember, these rules were designed before IPv6 when there were much harder limits placed on networks.
- 10.0.0.0 – 10.255.255.255 supports a total of 16,777,216 addresses and is classed as a single class A network.
- 172.16.0.0 – 172.31.255.255 supports a total of 1,048,576 addresses and is classed as a 16 contiguous class Bs network.
- 192.168.0.0 – 192.168.255.255 supports a total of 65,536 addresses and is classed as a 256 contiguous class Cs.
Simple, right?
In simple terms;
- Use 192 IP ranges whenever you have a small number of devices connected, i.e. a home environment
- Use 172 IP ranges whenever you have a medium number of devices connected, i.e. a small business and/or cloud environment that is regionalised. Notice how AWS uses the 172 ranges in EC2 instance hostnames
- Use 10 IP ranges whenever you want maximum control for how the maximum number of devices such as on private networks.
This helps you to determine which of the IP address ranges you are best to use. There are also considerations around network sizes and subnets but again, we’ll cover this in other blog posts.
by Michael Cropper | Jun 23, 2020 | Developer |
We’ve already done a long write up about debugging email deliverability issues so I’m not going to go over similar topics here. On the other side of the fence, once you’ve ruled out issues with emails being delivered you’re going to want to focus on the quality of the delivery to ensure your emails don’t get triggered as spam by spam filters. Thankfully there are a lot of technical things you can do to ensure your emails get delivered successfully. All of which I’m not going to go into the details here about what they all mean and how they work. In essence all you need to do is use the handy tool Mail Tester and that will talk you through everything you need to do. It is a seriously awesome tool to give you the knowledge and actionable steps you need to take to increase the quality of your emails to ensure your emails get straight through to your users priority inbox and not their spam box.
by Michael Cropper | Jun 14, 2020 | Developer |
At some point in time you’re going to need to migrate a WordPress website from one web server to another web server. Whether that is because you’re moving your own website to another web server, or if you are moving your WordPress website from WordPress.com over to your own self-hosted WordPress setup on your web server.
Thankfully there is a really handy plugin available which allows you to easily migrate your WordPress website with relative ease, and that plugin is called All-in-One WP Migration. But, the WordPress migration is just one part of the process and you need to make sure you’ve got your activities in line to avoid any disruption to your website. We’ve already covered topics such as How to Migrate a Web Server Seamlessly with Zero Downtime and How to Migrate an Ecommerce Website between Servers with Zero Downtime previously, so to avoid repeating a lot of the other considerations you need to take into account we’ll be omitting them from this blog post. So we’ll be purely focusing on how to use the All-in-One WP Migration plugin.
Step 1 – Download your Website
Firstly, download and install the All-in-One WP Migration plugin via the usual route on the website you are looking to migrate elsewhere. Once installed go to, WordPress Admin > All-in-One WP Migration > Export and select where you would like to export the website to. I’d recommend exporting to File as this will download the website to the computer you are doing this work on. Exporting to File will make your life a little easier in the next step which is to import the website into a new installation.
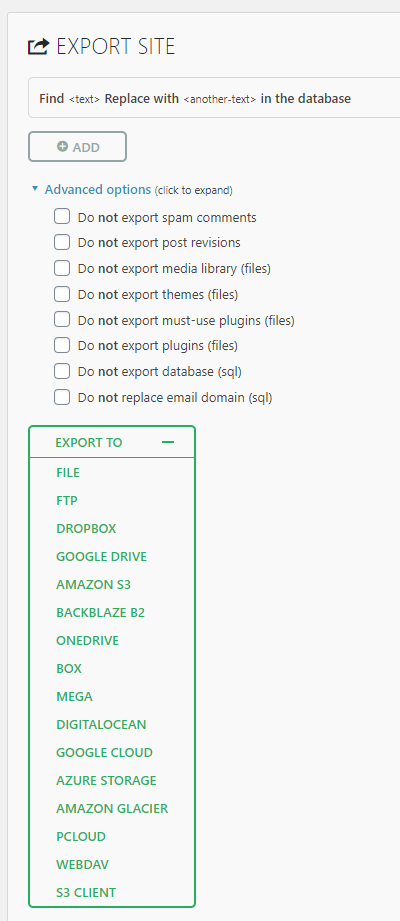
This option will download your entire website including files and database content.
Step 2 – Install WordPress on the New Web Server
Now you need to prepare the new web server. Ideally you’d do this before so you have time to iron out any kinks. You need to install WordPress via the usual mechanism you do this. This can vary between servers and web hosts or using the famous WordPress one-click-install option.
Once you’ve installed WordPress on the new web server you’ll need to install the All-in-One WP Migration plugin again.
Step 3 – Upload your Backup File
Now it’s time to upload the backup file from Step 1 to your WordPress installation on the new web server as outlined in Step 2. Important to note that many web servers out of the box limit the file upload size to around 2mb, so it’s likely you’ll need to temporarily increase the max_file_size and max_post_size settings within your php.ini file to make sure it is large enough to handle the upload.
To import your backup file simple navigate to, WordPress Admin > All-in-One WP Migration > Import, and you can import your backup file easily;
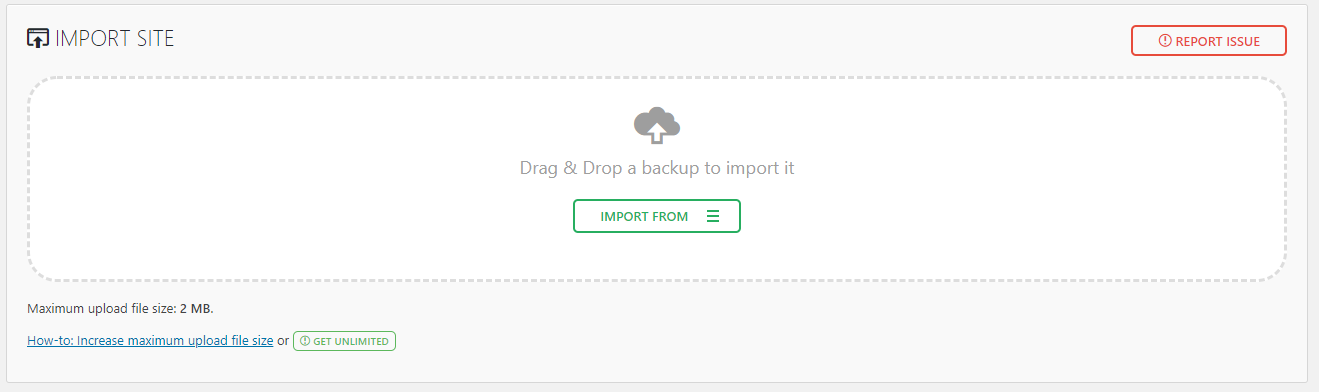
Once this has complete you’ll need to login to the website again as the default username and password you created in Step 2 will have been overwritten by the username and password that you used on the website when it was hosted on the old web server.
Summary
And it really is that simple to migrate a WordPress website between web servers or from WordPress.com over to a self-hosted version of WordPress. Naturally there are a lot of nuances along the way when working with web servers, DNS and file transfers so if you haven’t done this before make sure you give this a go on a test website initially. For low traffic websites the risk is extremely low. But for high traffic websites, ecommerce websites or heavily integrated websites then you need to plan these activities in a lot more detail to ensure its clear what the steps are to complete this successfully in the first run. There are often a lot more things to think about along the way, for example you may have a Mail Server or FTP server or non-WordPress databases also running on the old web server – you need to consider how you’re going to migrate these things as part of the process too if you’re using those. Some setups are simpler than others, but always consider as much as you can to minimise any issues during a migration.
by Michael Cropper | May 18, 2020 | Developer |
If you can remember all the cryptic commands within the Vi text editor on Linux then you are some kind of genius. For us mere mortals, the quickest way to edit files on Linux is to bin off Vi and move over to Nano. There, I said it, get over it. Nano is better than Vi hands down.
But in the unfortunate event you need to do a bit of Vi work before you can move over to Nano, for example to configure a network configuration file or to configure a Yum repositories configuration file for example, then you need to know how to work with Vi so you can get through that painful process as quick as possible.
Here are some handy Vi commands;
- Open a file: vi filename.txt
- Edit the file – aka. go into ‘insert mode’: Press the letter ‘i’ once you have opened the file
- Change what ever you need to do as usual
- Exit from Insert Mode: Press ESC
- Prepare to exit the file: Press colon :
- Now save and exit the file: Press, wq, then enter
- Whoops I messed up: Within Vi there are so many commands that seem to just utterly break the editor unless you know what they do that is can be difficult to exit out of the thing. If in doubt press ESC or CTRL + Q or CTRL + C and you should get back to where you need. Then exit the file without saving by pressing, :, q!, enter
I mean, simple, right?!?! Anyhow, that’s how you quickly edit the files you need and recover from when Vi has gone a bit crazy.
by Michael Cropper | May 18, 2020 | Developer |
Out of the box on CentOS 7 the default file editor is Vi, not Nano. And for any humans around, using Vi is beyond the reach of the mere mortals. Hey, if you can use Vi, then great, you can be on your merry way. But for the average user (like me!) then Nano is by far the easier option when it comes to working with editing files on Linux and CentOS 7.
Thankfully CentOS 7 also comes with Yum installed out of the box which is quite handy. Although if you’re playing with a complete fresh install, make sure your CentOS 7 box can connect to the internet as Ethernet is disabled out of the box too. I mean, who needs to access the internet, right…? So, assuming your all good to go based on the above, simply run the following command to get Nano installed on your system;
yum install nano
And that’s it, your download will start and you’ll be good to use Nano in no time at all.
by Michael Cropper | Apr 2, 2020 | Developer |
A common requirement for any project is to track the created and updated date/time stamp information. Thankfully with MySQL this is a relatively straight forward task… well, at least at the pure database level.
It is always recommended to track when your records were created and updated within all tables in your database as you can guarantee that at the point when you need it most, if you don’t have it you’ll regret not having it. Particularly when debugging problems and investigating issues.
Databases rarely live in isolation these days and there are many ways of logging the created and updated times. For example, you could within your web application actually generate the timestamp for all of your Insert and Update statements throughout your codebase and that is one perfectly good way of doing it. But let’s be honest, who has time for that. This approach comes with a lot of overhead for basic requirements although it is often essential to go down this approach for more complex requirements. But for now, let’s keep things simple.
MySQL is extremely powerful when it comes to managing your data. The two commands we’re going to take a look at for this are;
DETAULT Command
As you can probably imagine, this defines the default value for a column in your table. This allows you to assign a default value of your choosing based on the data type. In this case, a TIMESTAMP field which tracks the date and time. For this you can set the default to be the CURRENT_TIMESTAMP which will automatically populate your column created_date_time with the current timestamp whenever a new row is inserted.
ON UPDATE Command
And you can probably guess what this command does too…. It does something whenever a row of data is updated. You can only have one column per table that uses the ON UPDATE command so use it wisely. Again, you simply say what you want to do ON UPDATE, in this case you again want to store the CURRENT_TIMESTAMP against the field updated_date_time.
Example Alteration to a Table
Below you can see an example of how you can alter one of your database tables to have the created_date_time and updated_date_time columns with the handy MySQL features turned on so that you never have to worry about when the record was created or updated.
ALTER TABLE your_table_name ADD COLUMN created_date_time TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP;
ALTER TABLE your_table_name ADD COLUMN updated_date_time TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP;
by Michael Cropper | Apr 2, 2020 | Developer |
For those core Java developers you will be very comfortable utilising the power of the Tomcat Manager to deploy your applications to your servers. But what happens when you’re working on a server that doesn’t have the usual Tomcat Manager available for you to use, just how do you go about deploying your application easily?
Thankfully, it is fairly straight forward to do, it just requires a couple more steps to get this working.
Ultimately your .war file for your Java web application is just a fancy .zip file and as such we can treat it as so. So follow the simple steps outlined below and you’ll have your Java WAR file deployed on cPanel in no time, all without using the Tomcat Manager.
- Within your IDE, Clean and Build your project to compile and package the war file so you’ll end up with a file here: /{IDE_FOLDER}/ExampleProject/dist/ExampleProject.war
- Rename this file to .zip
- Login to your cPanel account and go to the File Manager
- Navigate to /public_html
- Create a folder called: Backup_yyyy_mm_dd (you know…. Just in case)
- Move all of your current files into the backup folder you just created (excluding any files that aren’t part of your project i.e. .htaccess file, cgi-bin, .well-known (SSL certificates with Let’s Encrypt) and any application live data files such as images or document uploads that only sit within your live system due to user usage etc.
- Upload your ExampleProject.zip file
- Unzip the file
- Done
Note, you shouldn’t need to restart Tomcat as all your new files should get automatically loaded into memory by Tomcat, but if you do notice that some files aren’t showing the latest version then you may need to restart Tomcat to ensure the files are all uploaded. To do this the handy command on the latest version of cPanel (at the time of writing!) is as follows. Simple SSH into your server or use the Terminal functionality that exists within cPanel and run the command;
ubic restart ea-tomcat85
This will restart the running Tomcat instance for your user only. Simple!
And if all has failed and you need to restore the backup files you backed up at the start, jump into your FTP Client software such as FileZilla where you can easily move all files within your backup folder back to the parent level. Unfortunately this part isn’t out of the box functionality with cPanel, so I’d make sure you can access your server using FileZilla before you attempt this process as you may need to quickly jump back on there and fix it.
by Michael Cropper | Mar 13, 2020 | Developer |
You’re probably looking for information on how to install multiple versions of Java on Linux as part of a migration piece of work and/or a new deployment activity after spinning up a new Linux server which has a different version of Java running than what your Java web application was compiled in. Whatever Java version your application is compiled in needs to be the same Java version that is running on your web application server to ensure it works without issues (or even just works!).
So, let’s assume you’ve got the handy yum tool installed on your Linux box which allows you to easily run handy commands to install software. Within yum you can find lots of handy versions of java just sitting around waiting to install them. Take a look at all the Java packages within yum.
What you’ll notice is that the majority of them are utilising the OpenJDK setup. This is a handy open source version of the Java platform. So all you need to do is get it installed then get it configured. Simple.
Check Current Java Version Installed
Firstly you need to check the current version of Java that you have installed on your Linux box. To do this simply run the following command;
java -version
Install Java 1.8 Version on Linux Using Yum
Simply run the following command to install the latest version of Java (whatever the latest version is on your system);
sudo yum instal java-1.8.0-openjdk
Configure Linux to Use the New Version of Java via Alternatives
On Linux machines you can configure multiple versions of Java to run via the ‘alternatives’ feature. This essentially allows you to install multiple Java versions alongside each other without having to worry about the specifics. This allows you to have multiple versions of Java installed, and still configure a default.
Which basically means that when you run any default java command that it will run against whatever alternative has been configured to point at the different versions of Java installed on your Linux box.
To check this, simply run the command;
sudo alternatives --config java
Which will allow you to configure which is the default Java version.
And it’s as simple as that. Install as many versions of Java as you need, but you can only use one of them at once.
If you have multiple applications running which all require different versions of Java then you have a couple of options. Either upgrade everything so they are all running the latest version of Java so you can keep everything on a single server. Or move applications to their own servers to give yourself the maximum control.
by Michael Cropper | Mar 10, 2020 | Developer |
So you’re running an Apache Tomcat environment on Linux but since this is a public facing web application, you want to get rid of the port 80 business so that your users don’t have to go remembering what port the application is running on. After all, port 8080 or 8084 isn’t exactly easy to remember for the average non-technical user. And god forbid you’ve decided to change this to something non-default, trying to remember that is going to be even more fun!
Thankfully it’s fairly straight forward to use Apache as a Reverse Proxy that sits in front of Apache Tomcat so that you can serve requests over port 80. You could configure Apache Tomcat to run on port 80, but if you’re running the Apache Tomcat Manager GUI then this restricts you to running your web applications only in sub-directories – and let’s be honest – no-one wants that. Everyone wants to be running their web application at the root of their domain, i.e. www.example.com rather than www.example.com/my-web-application/.
Configure an Apache Virtual Host File
Simply SSH into your server and run the command below;
sudo nano /etc/httpd/conf.d/httpd.conf
It’s worth nothing to double check the other files that currently exist in that directory before configuring this. Sometimes you will have slightly differently named files and/or this file may already exist with current configurations. Don’t just go adding configurations to this fil unless you’re sure what you are doing. At least take a backup of the current file(s) so you can revert your changes if you mess things up.
Thankfully on many vanilla installations of Apache this file will not exist, so the nano command above will create the file so you can edit it straight away.
To keep things simple all you need to do is add the following lines of code to that file;
<VirtualHost www.example.com:80>
ProxyPreserveHost On
ProxyPass / http://127.0.0.1:8080/
ProxyPassReverse / http://127.0.0.1:8080/
</VirtualHost>
Now run the command to restart Apache to ensure the changes take effect.
sudo service httpd restart
Now you’ll notice that the above doesn’t actually change anything. It just means the Apache Tomcat Manager GUI now loads over port 80 rather than port 8080. That isn’t quite what we want, so we need to configure the Virtual Hosts file to suit your application needs.
Let’s say your application is called MyWebApplication, which sits at www.example.com:8080/MyWebApplicaion on Apache Tomcat. You need to ensure your Virtual Hosts file looks as follows so that the application routes successfully;
<VirtualHost www.example.com:80>
ProxyPreserveHost On
ProxyPass / http://127.0.0.1:8080/MyWebApplication
ProxyPassReverse / http://127.0.0.1:8080/ MyWebApplication
</VirtualHost>
Simple. Now you’re done.
This is how you configure Apache as a Reverse Proxy for Apache Tomcat. This approach also allows you to run multiple Java web applications from a single Apache Tomcat instance if that suits your needs from a practical, management and security perspective. Alternatively, run everything from separate setups if you need something more segmented.
by Michael Cropper | Feb 16, 2020 | Developer |
Ok, this one is a little tricky as there isn’t a lot of authoritative and clear information online about how to do this, so I thought it would help to clarify how to do this as it’s a problem I just came across myself and spent a fair amount of time to get this working. Thankfully, this blog post should allow you to just read through it and be able to start converting SVG image to a PNG image in no time.
SVG to PNG Libraries
Firstly let’s look at the core libraries you need to do this. Thankfully there is just the one which is the Apache Batik library which is part of the Apache XML Graphics Project. In summary, Apache Batik is a Java-based toolkit for applications or applets that want to use images in the Scalable Vector Graphics (SVG) format for various purposes, such as display, generation or manipulation.
Now, this is where things start to get a little more challenging. I would recommend downloading the Bin ZIP file from the download link just mentioned. If you take a look around the Maven Repository you’ll notice that there are a lot of different versions which look all very similar, and all of them are generally last updated around 10 years ago. Sure, these things of tools rarely change once built, but this always worries me.
Once you’ve extracted the ZIP, you’re looking for the file titled batik-all-1.12.jar (Note, the version number may differ when you are reading this…) which will be in the folder, /batik-bin-1.12/batik-1.12/lib/batik-all-1.12.jar.
Add that JAR file to your project.
Now you would think that the project developers would have included all of the dependencies already bundled up. But no. And the documentation isn’t clear about all the dependencies which makes life even more difficult.
Dependencies
So, you need a few dependencies to get this up and running.
XML Commons from the Apache Xerces project
Download XML Commons and add the two JAR files to your project called, xml-apis.jar and xml-apis-ext.jar.
XML Graphics Commons from the Apache XML Graphics Project
Yes, this is the same project as where Batik lives, but hey. Download XML Graphics Commons and add the xmlgraphics-commons-2.4.jar file to your project.
Java Code to Convert an SVG into a PNG
Ok, so now we’ve got all the libraries and dependencies added to your project, it’s now time to actually write the code to convert an SVG to a PNG. Use this code as a starting point to get you going;
try {
// Use this to Read a Local Path
// String svgUriImputLocation = Paths.get("https://www.contradodigital.com/logo.svg").toUri().toURL().toString();
// Read Remote Location for SVG
String svgUriImputLocation = "https:// www.contradodigital.com/logo.svg";
TranscoderInput transcoderInput = new TranscoderInput(svgUriImputLocation);
// Define OutputStream Location
OutputStream outputStream = new FileOutputStream("C:\\Users\\{{Your User Name on Windows}}\\Documents\\logoAsPngFile.png");
TranscoderOutput transcoderOutput = new TranscoderOutput(outputStream);
// Convert SVG to PNG and Save to File System
PNGTranscoder pngTranscoder = new PNGTranscoder();
pngTranscoder.transcode(transcoderInput, transcoderOutput);
// Clean Up
outputStream.flush();
outputStream.close();
} catch (IOException | TranscoderException ex) {
System.out.println("Exception Thrown: " + ex);
}
Hope that helps to get you going in the right direction if you’re working on a similar problem to this.